Inledning
Jag har nyligen byggt ut en serverlös applikation på AWS som interagerar med Amazon QLDB som en specialbyggd databas i backend. I många fall kan några enkla konfigurationsändringar ha en dramatisk inverkan på prestandan. Det här inlägget tittar på några gratisverktyg och tjänster som du kan använda för att hjälpa till att optimera din egen serverlösa applikation. I demonstrationssyfte fokuserar jag på QLDB men ger också en kort jämförelse med DynamoDB.
Följande verktyg används:
- Artilleri för att generera last
- Faker för att generera falska data
- Serverlöst webbpaket för att bunta moduler
- Lumigo CLI som tillhandahåller en samling användbara kommandon
- AWS Lambda Power Tuning för optimal Lambda-konfiguration
- CloudWatch Log Insights för att söka efter data i logggrupper
- AWS X-Ray för analys av servicesamtal
QLDB Perf Test GitHub-arkivet innehåller koden som används för dessa tester.
Arkitektur
Demoapplikationen för prestandatest har följande arkitektur:
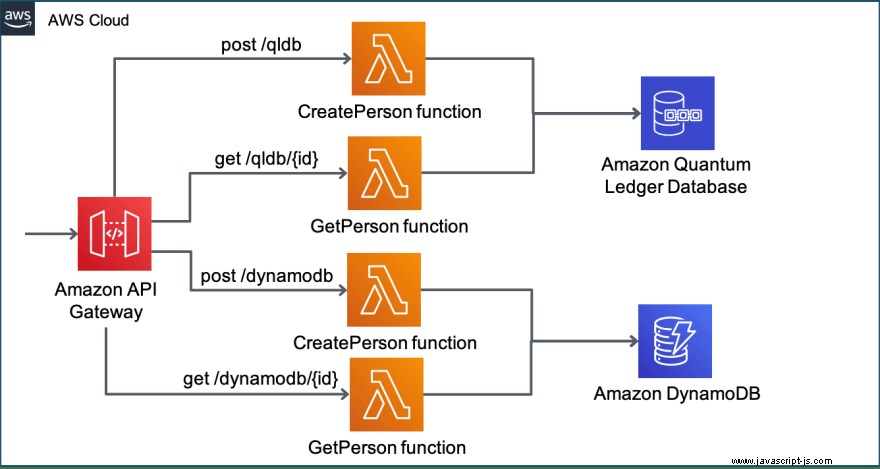
Den är konfigurerad med hjälp av Serverless Framework för att säkerställa att allt hanteras som kod i en CloudFormation-stack och kan distribueras eller tas bort när som helst.
Implementera
För att distribuera stacken kör följande kommando:
sls deploy
resources avsnittet i serverless.yml filen innehåller rå CloudFormation-mallsyntax. Detta låter dig skapa DynamoDB-tabellen samt attribut som beskriver nyckelschemat för tabellen och indexen, och de som utgör primärnyckeln. QLDB är helt schemalöst och det finns inget CloudFormation-stöd för att skapa tabeller eller index. Detta kan göras med hjälp av en anpassad resurs. Men för det här testet loggade jag bara in på konsolen och körde följande PartiQL-kommandon:
CREATE TABLE Person
CREATE INDEX ON Person (GovId)
Skapa testdata
Nästa steg är att skapa testdata med Faker och Artillery . Det första steget är att skapa ett enkelt artilleriskript för att lägga till en ny person i tabellen i QLDB (och ett separat skript för DynamoDB). Själva skriptet visas nedan:
config:
target: "{url}"
phases:
- duration: 300
arrivalRate: 10
processor: "./createTestPerson.js"
scenarios:
- flow:
# call createTestPerson() to create variables
- function: "createTestPerson"
- post:
url: "/qldb/"
json:
GovId: "{{ govid }}"
FirstName: "{{ firstName }}"
LastName: "{{ lastName }}"
DOB: "{{ dob }}"
GovIdType: "{{ govIdType }}"
Address: "{{ address }}"
config avsnittet definierar målet. Detta är webbadressen som returneras som en del av distributionen av stacken. config.phases tillåter mer sofistikerade laddningsfaser att definieras, men jag gick på ett enkelt test där 10 virtuella användare skapas varje sekund under totalt 5 minuter. config.processor attribut pekar på JavaScript-filen för att köra anpassad kod.
scenarios avsnittet definierar vad de virtuella användarna skapat av Artillery kommer att göra. I fallet ovan gör den ett HTTP POST med JSON-kroppen fylld med variabler hämtade från createTestPerson fungera. Detta är en modul som exporteras i JavaScript-filen som ser ut som följer:
function createTestPerson(userContext, events, done) {
// generate data with Faker:
const firstName = `${Faker.name.firstName()}`;
...
// add variables to virtual user's context:
userContext.vars.firstName = firstName;
...
return done();
}
module.exports = {
createTestPerson
};
I git-förvaret har följande skript definierats:
- create-qldb-person.yml
- create-dynamodb-person.yml
- get-qldb-person.yml
- get-dynamodb-person.yml
Det finns också några node skript som kan köras lokalt för att fylla i en CSV-fil som används för laddningstestförfrågningar. Dessa kan köras med följande kommandon:
node getQLDBPerson > qldbusers.csv
node getDynamoDBPerson > dynamodbusers.csv
Kör ett baslinjetest
Till att börja med körde jag ett baslinjetest som skapade 3000 nya poster under en 5 minuters period med följande kommando:
artillery run create-qldb-person.yml
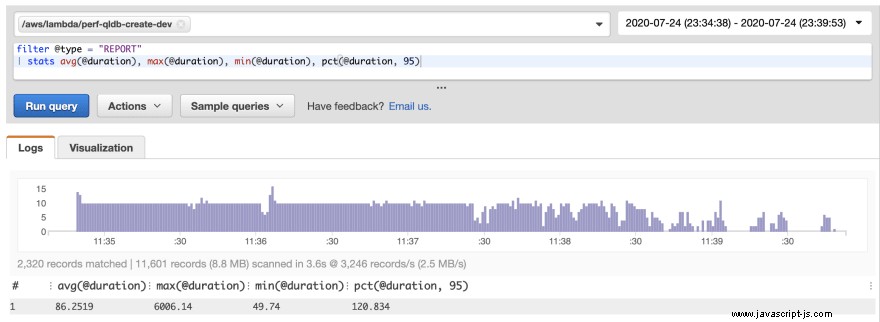
Utgången säger mig att skivorna skapades framgångsrikt, men ingenting kring framförandet. Lyckligtvis rapporterar alla Lambda-funktioner mätvärden via Amazon CloudWatch. Varje anrop av en lambdafunktion ger detaljer om den faktiska varaktigheten, fakturerad varaktighet och mängden minne som används. Du kan snabbt skapa en rapport om detta med CloudWatch Log Insights. Följande är frågan jag körde i Log Insights, följt av den resulterande rapporten som skapades:
filter @type = "REPORT"
| stats avg(@duration), max(@duration), min(@duration), pct(@duration, 95)
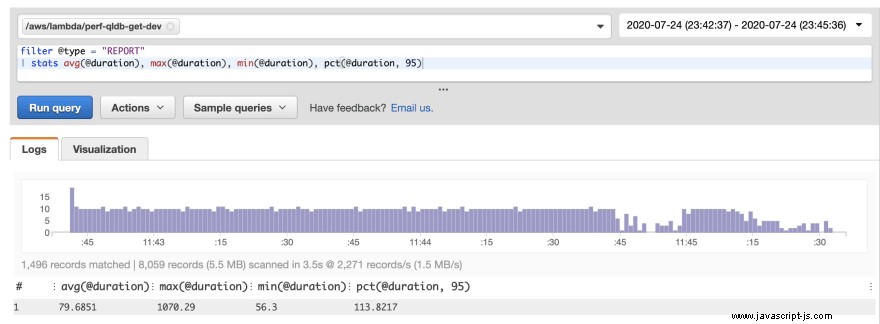
Att köra baslinjetestets frågedata gav i stort sett liknande resultat:
Aktivera HTTP Keep Alive
Den första optimeringen med Nodejs är att uttryckligen aktivera Keep-alive. Detta kan göras för alla funktioner med hjälp av följande miljövariabel:
environment:
AWS_NODEJS_CONNECTION_REUSE_ENABLED : "1"
Detta skrevs först av Yan Cui och verkar vara unikt för AWS SDK för Node, som skapar en ny TCP-anslutning varje gång som standard.
Genom att köra testerna igen sågs en betydande prestandaförbättring:
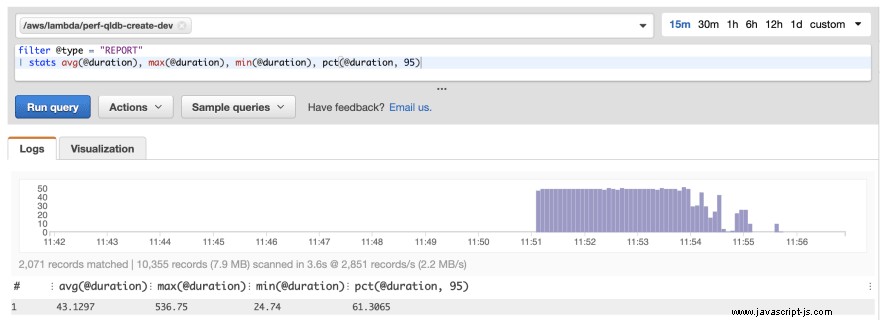
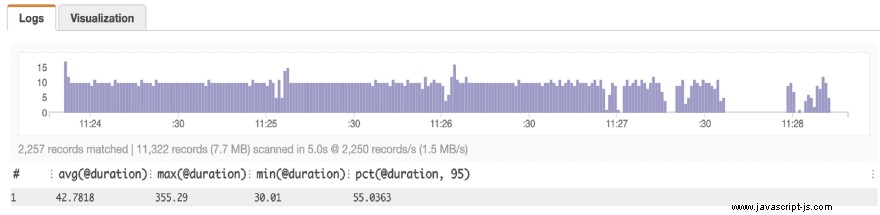
Den genomsnittliga svarstiden har ungefär halverats. Detta gäller även för P95-värdet. För dessa förfrågningar halverar det också kostnaden för lambdaanropet. Detta beror på att lambdapriset debiteras per 100 ms.
Bygg funktioner med Webpack
Nästa optimering är att titta på kallstarttiderna. När stacken först distribuerades ser vi storleken på artefaktutdata när vi kör sls deploy :
Serverless: Uploading service qldb-perf-demo.zip file to S3 (10.18 MB)...
Ett annat briljant verktyg är lumigo-cli . Denna har ett kommando som kan köras för att analysera lambda kallstarttider. Jag körde det här kommandot för att analysera alla kallstarter för en specifik lambdafunktion under de senaste 30 minuterna:
lumigo-cli analyze-lambda-cold-starts -m 30 -n perf-qldb-get-dev -r eu-west-1
Detta gav följande utdata:

För att optimera kallstarttider använde jag webpack som en statisk modulbuntare för JavaScript. Detta fungerar genom att gå igenom ditt paket och skapa en ny beroendegraf, som bara drar ut de moduler som krävs. Det skapar sedan ett nytt paket som endast består av dessa filer. Denna trädskakning kan resultera i en avsevärt reducerad förpackningsstorlek. En kallstart för en lambdafunktion innebär att man laddar ner distributionspaketet och packar upp det innan anropet. En reducerad förpackningsstorlek kan resultera i en kortare kallstarttid.
Jag använde serverless-webpack plugin och la till följande till serverless.yml fil:
custom:
webpack:
webpackConfig: 'webpack.config.js'
includeModules: false
packager: 'npm'
Jag skapade sedan webpack.config.js fil som anger ingångspunkterna för lambdafunktionerna:
module.exports = {
entry: {
'functions/perf-qldb-create': './functions/perf-qldb-create.js',
'functions/perf-qldb-get': './functions/perf-qldb-get.js',
'functions/perf-dynamodb-create': './functions/perf-dynamodb-create.js',
'functions/perf-dynamodb-get': './functions/perf-dynamodb-get.js',
},
mode: 'production',
target: 'node'
}
Effekten av att bunta distributionspaketet med hjälp av webpack kan ses när stacken omdistribueras:
Serverless: Uploading service qldb-perf-demo.zip file to S3 (1.91 MB)...
Med minimal ansträngning har vi minskat paketstorleken med över 80 %. Att köra om belastningstester och använda lumigo-cli för att analysera kallstarterna resulterade i följande:
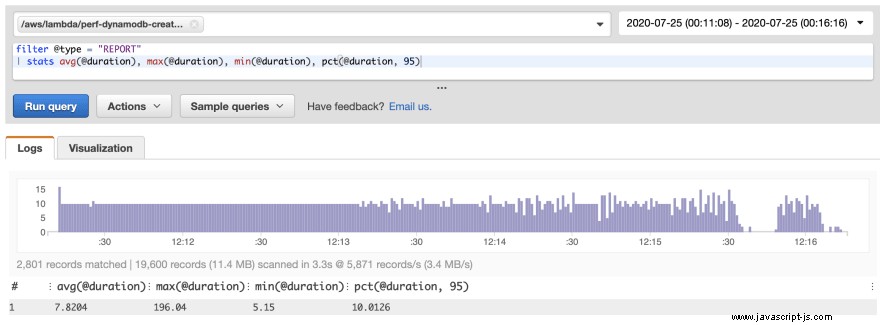
Detta resulterade i en 200 ms minskning av initialiseringstiden för kallstarter, en minskning med 40 %.
Optimera Lambda-konfigurationen
Den sista kontrollen var att använda den fantastiska AWS Lambda Power Tuning öppen källkodsverktyg av Alex Casalboni. Detta använder stegfunktioner på ditt konto för att testa olika minnes-/strömkonfigurationer. Detta kräver en händelsenyttolast för att passera in. Jag använde följande loggsats för att skriva ut händelsemeddelandet för en inkommande begäran i lambdafunktionen.
console.log(`** PRINT MSG: ${JSON.stringify(event, null, 2)}`);
Jag kopierade sedan händelsemeddelandet till en fil som heter qldb-data.json , och körde följande kommando:
lumigo-cli powertune-lambda -f qldb-data.json -n perf-qldb-get-dev -o qldb-output.json -r eu-west-1 -s balanced
Detta genererade följande visualisering:
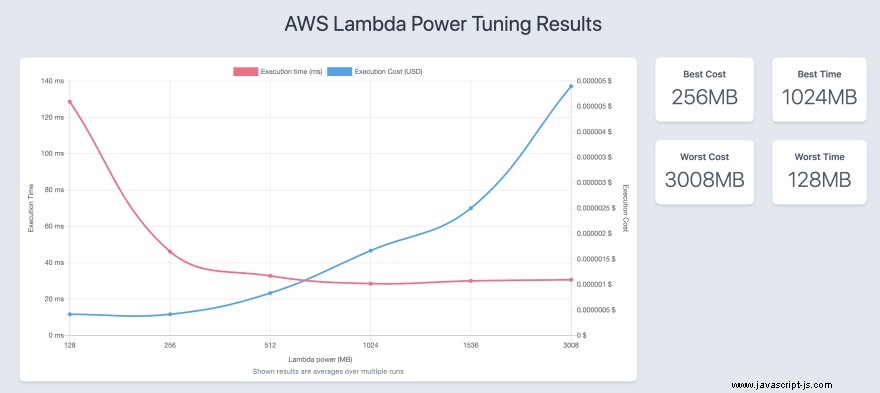
I det här fallet fungerar det bäst att ha en minnesallokering på 512 MB när det gäller avvägningen mellan kostnad och prestanda.
DynamoDB-jämförelse
Samma verktyg användes på DynamoDB för att optimera prestandan direkt, med liknande förbättringar. Den slående skillnaden är att den genomsnittliga fördröjningen för både skapande och gets var ensiffrig millisekund som visas nedan:
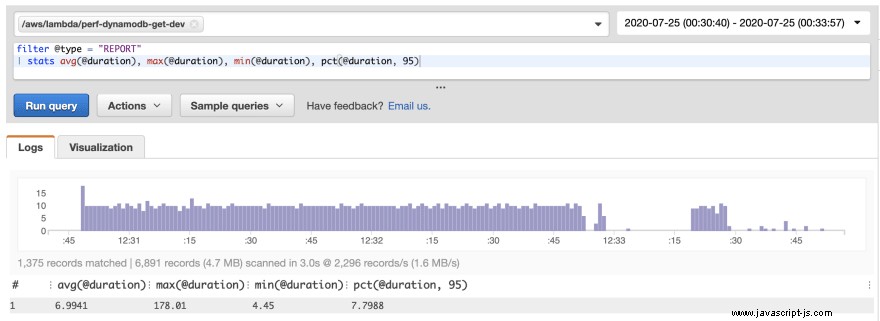
Det märktes också att den genomsnittliga kallstarttiden (dock med en minimal datauppsättning) var cirka 40 % mindre än den för QLDB.

Med vissa tjänster finns det även ytterligare mätvärden som kan analyseras. Till exempel har DynamoDB en omfattande uppsättning mätvärden som är tillgängliga att se i konsolen, såsom läs- och skrivkapacitet, begränsade förfrågningar och händelser och latens. Använda verktyg som Artillery i kombination med Faker ger tillgång till dessa mätvärden som kan hjälpa till att optimera prestandan ytterligare. Följande diagram visar skrivkapacitetsenheterna som förbrukas av DynamoDB under de 5 minuterna av en av testkörningarna.
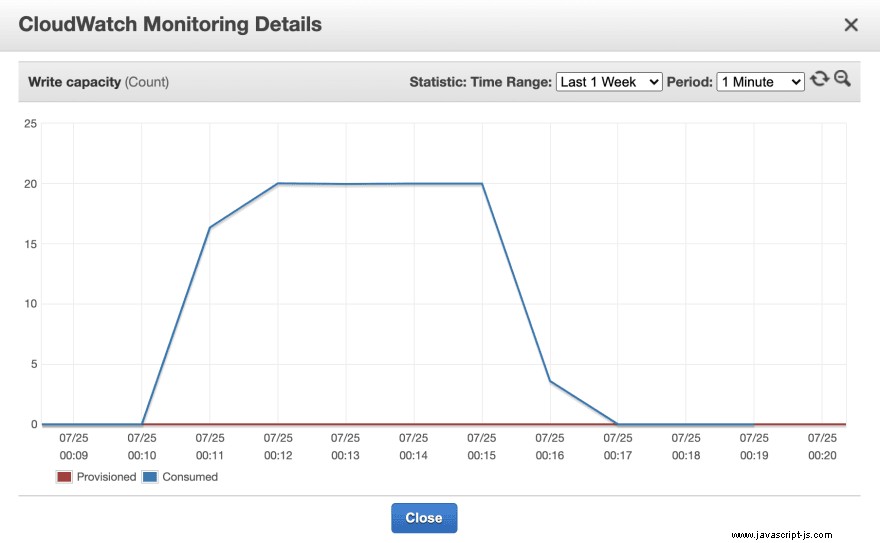
Men innan du drar en slutsats är det också värt att förstå vad som händer under ett servicesamtal med hjälp av ett annat verktyg som heter AWS X-Ray.
AWS X-Ray
AWS X-Ray används för att spåra förfrågningar genom en applikation. För att spåra latensen för AWS-tjänsten kan X-Ray SDK auto-instrumenteras med en enda linje:
const AWSXRay = require('aws-xray-sdk-core');
const AWS = AWSXRay.captureAWS(require('aws-sdk'));
Spårade AWS-tjänster och resurser som du kommer åt visas som nedströmsnoder på tjänstekartan i röntgenkonsolen. Servicekartan för lambdafunktionen som hämtar data från QLDB visas nedan:
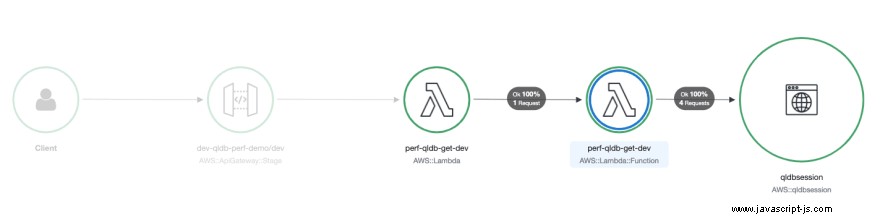
Den mest slående observationen är att varje begäran resulterar i 4 anrop till QLDB-sessionsobjektet. Du kan se detta mer i detalj genom att analysera spårdetaljerna för enskilda förfrågningar. Den nedan är vald eftersom den inte bara visar 4 SendCommand samtal, men Initialization värdet visar att detta var en kallstart.

All interaktion med QLDB utförs med hjälp av QLDB-drivrutinen, som tillhandahåller ett abstraktionsskikt på hög nivå ovanför QLDB Session dataplan och hanterar SendCommand API kräver dig. Detta inkluderar den nödvändiga SendCommand samtal till StartTransaction , ExecuteStatement och CommitTransaction . Detta beror på att QLDB-transaktioner är ACID-kompatibla och har full serialiserbarhet - den högsta nivån av isolering. QLDB i sig är implementerat med en journal-first-arkitektur, där ingen post kan uppdateras utan att gå igenom journalen först, och journalen innehåller endast engagerade transaktioner.
När som helst kan du exportera journalblocken i din reskontra till S3. Ett exempel på ett journalblock som togs när jag exporterade reskontran visas nedan:
{
blockAddress: {
strandId:"Djg2uUFY81k7RF3W6Kjk0Q",
sequenceNo:34494
},
transactionId:"BvtWxFcAprL46H8SUO4UNB",
blockTimestamp:2020-07-29T14:36:46.878Z,
blockHash:{{VWrBpXNsFqrakqlyqCYIQA85fVihifAC8n4NjRHQF1c=}},
entriesHash:{{dNkwEyOukyqquu0qGN1Va+M/wZoM6ydpeVym2SjPYHQ=}},
previousBlockHash:{{ZjoCeXoOtZe/APVp2jAuKILnzPfXNIIDxAW8BHQ6L0g=}},
entriesHashList:[{{f+ABhLyvVPWxQpTUIdCInfBxf/VeYUAqXgfbhVLn/hI=}},
{{}},
{{ExVOMej9pEys3rU1MEZyNtHaSSt5KnaFvFQYL3qPO2w=}}],
transactionInfo: {
statements:[{
statement:"SELECT * FROM Person AS b WHERE b.GovId = ?",
startTime:2020-07-29T14:36:46.814Z,
statementDigest:{{scNEggVYz4buMxYEBvIhYF8N23+0p2huMD37bCaoKjE=}}
}]
}
}
{
blockAddress: {
strandId:"Djg2uUFY81k7RF3W6Kjk0Q",
sequenceNo:34495
},
transactionId:"IyNXk5JJyb5L8zFYifJ7lu",
blockTimestamp:2020-07-29T14:36:46.879Z,
blockHash:{{QW6OILb/v7jwHtPhCxj4bh0pLlwL7PqNKfi7AmNZntE=}},
...
Detta visar att även när man utför ett urvalsutdrag mot reskontran, sker det inom en transaktion, och detaljerna för den transaktionen committeras som ett nytt journalblock. Det finns inga dokumentrevisioner kopplade till blocket, eftersom inga data har uppdaterats. Sekvensnumret som anger platsen för blocket ökas. När en transaktion genomförs beräknas en SHA-256-hash och lagras som en del av blocket. Varje gång ett nytt block läggs till kombineras hashen för det blocket med hashen från föregående block (hash-kedja).
Slutsats
Det här inlägget har visat hur du använder några gratisverktyg och tjänster för att optimera dina serverlösa applikationer. Från baslinjetestet för interaktion med QLDB har vi:
- Reducerade genomsnittliga svarstider med ~50 %
- Reducerade kallstartskostnader med ~40 %
- Reducerad paketstorlek med ~80 %
- Välj den lämpligaste minnesstorleken för våra Lambda-funktioner
Vi har slutat med inlägg och frågor till QLDB som svarar på cirka 40 ms. Detta ger oss också fullt serialiserbart transaktionsstöd, en garanti för att endast registrerad data finns i journalen, oföränderlig data och möjligheten att krytografiskt verifiera statusen för en post som går tillbaka till vilken tidpunkt som helst för att uppfylla revisions- och efterlevnadskrav. Allt detta tillhandahålls direkt med en helt schemalös och serverlös databasmotor, och vi behövde inte konfigurera våra egna VPC:er.
Användningen av DynamoDB i det här inlägget var att visa hur verktygen kommer att fungera för att optimera Lamda-funktioner som interagerar med vilken tjänst som helst. Men det understryker också att det är viktigt att välja rätt tjänst för att möta dina krav. QLDB är inte designat för att tillhandahålla den ensiffriga millisekundslatens som DynamoDB kan. Men om du har komplexa krav som täcker både granskning och efterlevnad och upprätthåller en sanningskälla, samt stödjer läsningar med låg latens och komplexa sökningar, kan du alltid strömma data från QLDB till andra specialbyggda databaser som jag visar i den här bloggen inlägg