===Per ricevere più articoli 👉 iscriviti alla newsletter sul blog ===
La creazione di software scalabile è un compito impegnativo. Quando pensiamo alla scalabilità nelle applicazioni front-end, possiamo pensare a una crescente complessità, a un numero sempre maggiore di regole aziendali, a una quantità crescente di dati caricati nell'applicazione e a grandi team spesso distribuiti in tutto il mondo. Al fine di affrontare i fattori menzionati per mantenere un'elevata qualità di consegna e prevenire l'indebitamento tecnico, è necessaria un'architettura solida e ben fondata. Angular stesso è un framework piuttosto supponente, costringendo gli sviluppatori a fare le cose nel modo corretto , eppure ci sono molti posti in cui le cose possono andare storte. In questo articolo, presenterò consigli di alto livello su un'architettura di applicazione angolare ben progettata, basata su best practice e modelli collaudati in battaglia. Il nostro obiettivo finale in questo articolo è imparare a progettare un'applicazione Angular al fine di mantenere una velocità di sviluppo sostenibile e facilità di aggiunta di nuove funzionalità a lungo termine. Per raggiungere questi obiettivi, applicheremo:
- corrette astrazioni tra i livelli dell'applicazione,
- flusso di dati unidirezionale,
- gestione dello stato reattivo,
- design modulare,
- Modello di componenti intelligenti e stupidi.
Problemi di scalabilità nel front-end
Pensiamo ai problemi in termini di scalabilità che possiamo affrontare nello sviluppo di moderne applicazioni front-end. Oggi, le applicazioni front-end non "solo visualizzano" i dati e accettano gli input degli utenti. Le applicazioni a pagina singola (SPA) offrono agli utenti interazioni avanzate e utilizzano il back-end principalmente come livello di persistenza dei dati. Ciò significa che molte più responsabilità sono state spostate nella parte front-end dei sistemi software. Ciò porta a una crescente complessità della logica front-end, con cui dobbiamo fare i conti. Non solo il numero di requisiti cresce nel tempo, ma anche la quantità di dati che carichiamo nell'applicazione. Inoltre, dobbiamo mantenere le prestazioni delle applicazioni, che possono essere facilmente danneggiate. Infine, i nostri team di sviluppo stanno crescendo (o almeno ruotano:le persone vanno e vengono) ed è importante che i nuovi arrivati si mettano al passo il più velocemente possibile.

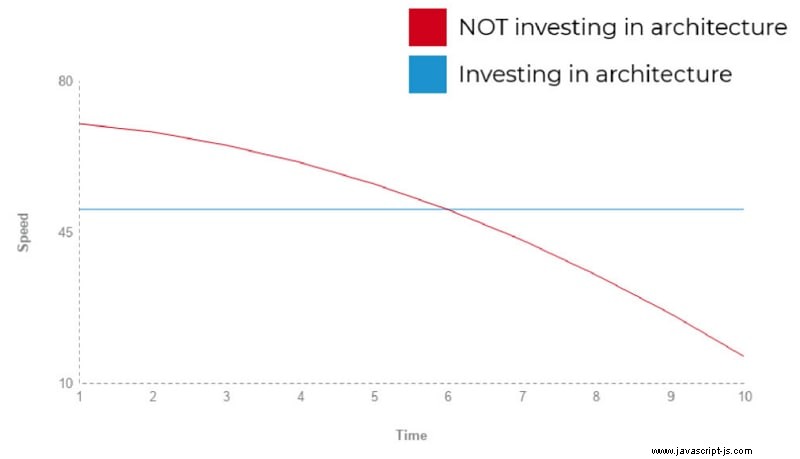
Una delle soluzioni ai problemi sopra descritti è un'architettura di sistema solida. Ma questo viene con il costo, il costo dell'investimento in quell'architettura sin dal primo giorno. Può essere molto allettante per noi sviluppatori fornire nuove funzionalità molto rapidamente, quando il sistema è ancora molto piccolo. In questa fase, tutto è facile e comprensibile, quindi lo sviluppo procede molto velocemente. Ma, a meno che non ci preoccupiamo dell'architettura, dopo alcune rotazioni degli sviluppatori, funzionalità complicate, refactoring, un paio di nuovi moduli, la velocità di sviluppo rallenta radicalmente. Il diagramma sottostante mostra come appariva di solito nella mia carriera di sviluppo. Questo non è uno studio scientifico, è solo come lo vedo io.
Architettura del software
Per discutere delle migliori pratiche e modelli di architettura, dobbiamo rispondere a una domanda, in primo luogo qual è l'architettura del software. Martin Fowler definisce l'architettura come "scomposizione di più alto livello di un sistema nelle sue parti ". Inoltre, direi che l'architettura del software descrive come il software è composto dalle sue parti e quali sono le regole e vincoli della comunicazione tra quelle parti. Di solito, le decisioni sull'architettura che prendiamo nello sviluppo del nostro sistema sono difficili da cambiare man mano che il sistema cresce nel tempo. Ecco perché è molto importante prestare attenzione a queste decisioni fin dall'inizio del nostro progetto, soprattutto se il software che costruiamo dovrebbe essere in produzione per molti anni. Robert C. Martin una volta disse:il vero costo del software è la sua manutenzione. Avere un'architettura ben fondata aiuta a ridurre i costi di manutenzione del sistema.
Livelli di astrazione di alto livello
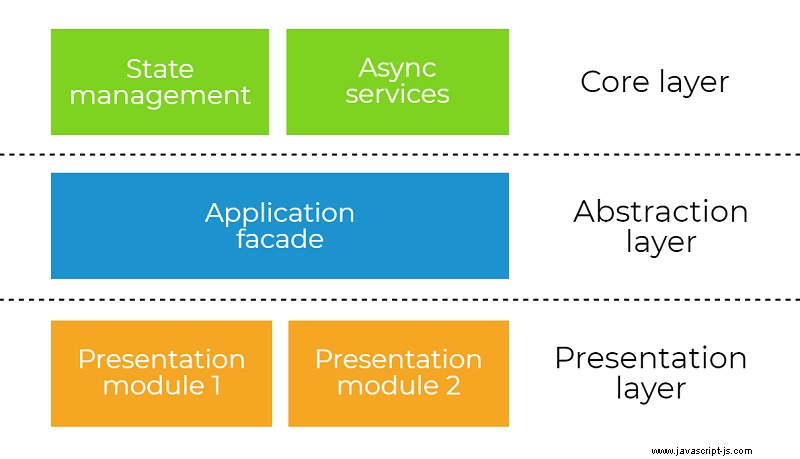
Il primo modo per decomporre il nostro sistema è attraverso i livelli di astrazione. Il diagramma sottostante illustra il concetto generale di questa scomposizione. L'idea è di porre la corretta responsabilità nel livello corretto del sistema:core , astrazione o presentazione strato. Esamineremo ogni livello in modo indipendente e analizzeremo la sua responsabilità. Questa divisione del sistema detta anche le regole di comunicazione. Ad esempio, la presentazione il livello può parlare con il nucleo livello solo tramite l'astrazione strato. Più avanti impareremo quali sono i vantaggi di questo tipo di vincolo.
Livello presentazione
Iniziamo ad analizzare la suddivisione del nostro sistema dal livello di presentazione. Questo è il luogo in cui vivono tutti i nostri componenti Angular. Le uniche responsabilità di questo livello sono di presentare e per delegare . In altre parole, presenta l'interfaccia utente e delega le azioni dell'utente al livello principale, attraverso il livello di astrazione. Sa cosa da visualizzare e cosa fare, ma non sa come le interazioni dell'utente dovrebbero essere gestite.
Sotto lo snippet di codice contiene CategoriesComponent utilizzando SettingsFacade istanza dal livello di astrazione per delegare l'interazione dell'utente (tramite addCategory() e updateCategory() ) e presentare uno stato nel suo modello (tramite isUpdating$ ).
@Component({
selector: 'categories',
templateUrl: './categories.component.html',
styleUrls: ['./categories.component.scss']
})
export class CategoriesComponent implements OnInit {
@Input() cashflowCategories$: CashflowCategory[];
newCategory: CashflowCategory = new CashflowCategory();
isUpdating$: Observable<boolean>;
constructor(private settingsFacade: SettingsFacade) {
this.isUpdating$ = settingsFacade.isUpdating$();
}
ngOnInit() {
this.settingsFacade.loadCashflowCategories();
}
addCategory(category: CashflowCategory) {
this.settingsFacade.addCashflowCategory(category);
}
updateCategory(category: CashflowCategory) {
this.settingsFacade.updateCashflowCategory(category);
}
}
Livello di astrazione
Il livello di astrazione disaccoppia il livello di presentazione dal livello principale e ha anche le proprie responsabilità definite. Questo livello espone i flussi di stato e interfaccia per i componenti nel livello di presentazione, svolgendo il ruolo della facciata . Questo tipo di facciata sabbiera cosa possono vedere e fare i componenti nel sistema. Possiamo implementare le facciate semplicemente usando i provider di classi Angular. Le classi qui possono essere nominate con Facciata suffisso, ad esempio SettingsFacade . Di seguito, puoi trovare un esempio di tale facciata.
@Injectable()
export class SettingsFacade {
constructor(private cashflowCategoryApi: CashflowCategoryApi, private settingsState: SettingsState) { }
isUpdating$(): Observable<boolean> {
return this.settingsState.isUpdating$();
}
getCashflowCategories$(): Observable<CashflowCategory[]> {
// here we just pass the state without any projections
// it may happen that it is necessary to combine two or more streams and expose to the components
return this.settingsState.getCashflowCategories$();
}
loadCashflowCategories() {
return this.cashflowCategoryApi.getCashflowCategories()
.pipe(tap(categories => this.settingsState.setCashflowCategories(categories)));
}
// optimistic update
// 1. update UI state
// 2. call API
addCashflowCategory(category: CashflowCategory) {
this.settingsState.addCashflowCategory(category);
this.cashflowCategoryApi.createCashflowCategory(category)
.subscribe(
(addedCategoryWithId: CashflowCategory) => {
// success callback - we have id generated by the server, let's update the state
this.settingsState.updateCashflowCategoryId(category, addedCategoryWithId)
},
(error: any) => {
// error callback - we need to rollback the state change
this.settingsState.removeCashflowCategory(category);
console.log(error);
}
);
}
// pessimistic update
// 1. call API
// 2. update UI state
updateCashflowCategory(category: CashflowCategory) {
this.settingsState.setUpdating(true);
this.cashflowCategoryApi.updateCashflowCategory(category)
.subscribe(
() => this.settingsState.updateCashflowCategory(category),
(error) => console.log(error),
() => this.settingsState.setUpdating(false)
);
}
}
Interfaccia di astrazione
Conosciamo già le principali responsabilità di questo livello; per esporre i flussi di stato e l'interfaccia per i componenti. Cominciamo con l'interfaccia. Metodi pubblici loadCashflowCategories() , addCashflowCategory() e updateCashflowCategory() astrarre i dettagli della gestione dello stato e le chiamate API esterne dai componenti. Non utilizziamo fornitori di API (come CashflowCategoryApi ) direttamente nei componenti, poiché vivono nello strato centrale. Inoltre, il modo in cui lo stato cambia non è una preoccupazione dei componenti. Al livello di presentazione non dovrebbe interessare come le cose sono fatte e i componenti dovrebbero chiamare semplicemente i metodi dal livello di astrazione quando necessario (delegato). L'esame dei metodi pubblici nel nostro livello di astrazione dovrebbe darci una rapida panoramica sui casi d'uso di alto livello in questa parte del sistema.
Ma dovremmo ricordare che il livello di astrazione non è un luogo in cui implementare la logica aziendale. Qui vogliamo solo connetterci il livello di presentazione alla nostra logica aziendale, astraendo il modo è connesso.
Stato
Quando si tratta dello stato, il livello di astrazione rende i nostri componenti indipendenti dalla soluzione di gestione dello stato. Ai componenti vengono forniti Osservabili con dati da visualizzare sui modelli (di solito con async pipe) e non mi interessa come e da dove provengono questi dati. Per gestire il nostro stato possiamo scegliere qualsiasi libreria di gestione dello stato che supporti RxJS (come NgRx) o utilizzare semplicemente BehaviorSubjects per modellare il nostro stato. Nell'esempio sopra stiamo usando un oggetto di stato che utilizza internamente BehaviorSubjects (l'oggetto di stato fa parte del nostro livello principale). Nel caso di NgRx, invieremo azioni per il negozio.
Avere questo tipo di astrazione ci dà molta flessibilità e permette di cambiare il modo in cui gestiamo lo stato senza nemmeno toccare il livello di presentazione. È anche possibile migrare senza problemi a un back-end in tempo reale come Firebase, rendendo la nostra applicazione tempo reale . Personalmente mi piace iniziare con BehaviorSubjects per gestire lo stato. Se in seguito, ad un certo punto dello sviluppo del sistema, c'è bisogno di usare qualcos'altro, con questo tipo di architettura è molto facile refactoring.

Strategia di sincronizzazione
Ora, diamo un'occhiata più da vicino all'altro aspetto importante del livello di astrazione. Indipendentemente dalla soluzione di gestione dello stato che scegliamo, possiamo implementare gli aggiornamenti dell'interfaccia utente in modo ottimista o pessimista. Immagina di voler creare un nuovo record nella raccolta di alcune entità. Questa raccolta è stata recuperata dal back-end e visualizzata nel DOM. In un approccio pessimistico, proviamo prima ad aggiornare lo stato sul lato backend (ad esempio con richiesta HTTP) e in caso di successo aggiorniamo lo stato nell'applicazione frontend. D'altra parte, in un approccio ottimista, lo facciamo in un ordine diverso. In primo luogo, assumiamo che l'aggiornamento del back-end avrà esito positivo e aggiornerà immediatamente lo stato del front-end. Quindi inviamo la richiesta per aggiornare lo stato del server. In caso di successo, non dobbiamo fare nulla, ma in caso di errore, dobbiamo ripristinare la modifica nella nostra applicazione frontend e informare l'utente di questa situazione.
Memorizzazione nella cache
A volte, potremmo decidere che i dati che recuperiamo dal back-end non faranno parte dello stato della nostra applicazione. Questo può essere utile per sola lettura dati che non vogliamo affatto manipolare e semplicemente passare (tramite il livello di astrazione) ai componenti. In questo caso, possiamo applicare la memorizzazione nella cache dei dati nella nostra facciata. Il modo più semplice per ottenerlo è usare shareReplay() Operatore RxJS che riprodurrà l'ultimo valore nel flusso per ogni nuovo abbonato. Dai un'occhiata allo snippet di codice qui sotto con RecordsFacade utilizzando RecordsApi per recuperare, memorizzare nella cache e filtrare i dati per i componenti.
@Injectable()
export class RecordsFacade {
private records$: Observable<Record[]>;
constructor(private recordApi: RecordApi) {
this.records$ = this.recordApi
.getRecords()
.pipe(shareReplay(1)); // cache the data
}
getRecords() {
return this.records$;
}
// project the cached data for the component
getRecordsFromPeriod(period?: Period): Observable<Record[]> {
return this.records$
.pipe(map(records => records.filter(record => record.inPeriod(period))));
}
searchRecords(search: string): Observable<Record[]> {
return this.recordApi.searchRecords(search);
}
}
Per riassumere, quello che possiamo fare nel livello di astrazione è:
- esporre i metodi per i componenti in cui noi:
- delega l'esecuzione della logica al livello principale,
- decidere sulla strategia di sincronizzazione dei dati (ottimista vs. pessimista)
- espone i flussi di stato per i componenti:
- scegli uno o più stream dello stato dell'interfaccia utente (e combinali se necessario)
- Memorizza nella cache i dati da un'API esterna.
Come vediamo, lo strato di astrazione gioca un ruolo importante nella nostra architettura a strati. Ha responsabilità chiaramente definite, ciò che aiuta a comprendere e ragionare meglio sul sistema. A seconda del tuo caso particolare, puoi creare una facciata per modulo angolare o una per ciascuna entità. Ad esempio, il SettingsModule può avere un singolo SettingsFacade , se non è troppo gonfio. Ma a volte potrebbe essere meglio creare facciate di astrazione più granulari per ciascuna entità individualmente, come UserFacade per User entità.
Strato centrale
L'ultimo strato è lo strato centrale. È qui che viene implementata la logica dell'applicazione principale. Tutte le manipolazioni dei dati e comunicazione con il mondo esterno succede qui. Se per la gestione dello stato stessimo utilizzando una soluzione come NgRx, qui è un posto dove inserire la nostra definizione di stato, azioni e riduttori. Poiché nei nostri esempi stiamo modellando lo stato con BehaviorSubjects, possiamo incapsularlo in una comoda classe di stato. Di seguito puoi trovare SettingsState esempio dal livello centrale.
@Injectable()
export class SettingsState {
private updating$ = new BehaviorSubject<boolean>(false);
private cashflowCategories$ = new BehaviorSubject<CashflowCategory[]>(null);
isUpdating$() {
return this.updating$.asObservable();
}
setUpdating(isUpdating: boolean) {
this.updating$.next(isUpdating);
}
getCashflowCategories$() {
return this.cashflowCategories$.asObservable();
}
setCashflowCategories(categories: CashflowCategory[]) {
this.cashflowCategories$.next(categories);
}
addCashflowCategory(category: CashflowCategory) {
const currentValue = this.cashflowCategories$.getValue();
this.cashflowCategories$.next([...currentValue, category]);
}
updateCashflowCategory(updatedCategory: CashflowCategory) {
const categories = this.cashflowCategories$.getValue();
const indexOfUpdated = categories.findIndex(category => category.id === updatedCategory.id);
categories[indexOfUpdated] = updatedCategory;
this.cashflowCategories$.next([...categories]);
}
updateCashflowCategoryId(categoryToReplace: CashflowCategory, addedCategoryWithId: CashflowCategory) {
const categories = this.cashflowCategories$.getValue();
const updatedCategoryIndex = categories.findIndex(category => category === categoryToReplace);
categories[updatedCategoryIndex] = addedCategoryWithId;
this.cashflowCategories$.next([...categories]);
}
removeCashflowCategory(categoryRemove: CashflowCategory) {
const currentValue = this.cashflowCategories$.getValue();
this.cashflowCategories$.next(currentValue.filter(category => category !== categoryRemove));
}
}
Nel livello principale, implementiamo anche query HTTP sotto forma di provider di classi. Questo tipo di classe potrebbe avere Api o Service suffisso del nome. I servizi API hanno una sola responsabilità:comunicare con gli endpoint API e nient'altro. Dovremmo evitare qualsiasi memorizzazione nella cache, logica o manipolazione dei dati qui. Di seguito è possibile trovare un semplice esempio di servizio API.
@Injectable()
export class CashflowCategoryApi {
readonly API = '/api/cashflowCategories';
constructor(private http: HttpClient) {}
getCashflowCategories(): Observable<CashflowCategory[]> {
return this.http.get<CashflowCategory[]>(this.API);
}
createCashflowCategory(category: CashflowCategory): Observable<any> {
return this.http.post(this.API, category);
}
updateCashflowCategory(category: CashflowCategory): Observable<any> {
return this.http.put(`${this.API}/${category.id}`, category);
}
}
In questo livello, potremmo anche posizionare eventuali validatori, mappatori o casi d'uso più avanzati che richiedono la manipolazione di molte sezioni del nostro stato dell'interfaccia utente.
Abbiamo trattato l'argomento dei livelli di astrazione nella nostra applicazione frontend. Ogni livello ha i suoi confini e responsabilità ben definiti. Abbiamo anche definito le rigide regole di comunicazione tra i livelli. Tutto questo aiuta a comprendere e ragionare meglio sul sistema nel tempo man mano che diventa sempre più complesso.
🚀 Per ricevere più articoli 👉 iscriviti alla newsletter sul blog 🚀
Flusso dati unidirezionale e gestione dello stato reattivo
Il prossimo principio che vogliamo introdurre nel nostro sistema riguarda il flusso di dati e la propagazione del cambiamento. Angular stesso utilizza il flusso di dati unidirezionale a livello di presentazione (tramite collegamenti di input), ma imporremo una restrizione simile a livello di applicazione. Insieme alla gestione dello stato reattivo (basata sui flussi), ci darà la proprietà molto importante del sistema:coerenza dei dati . Il diagramma sottostante presenta l'idea generale del flusso di dati unidirezionale.
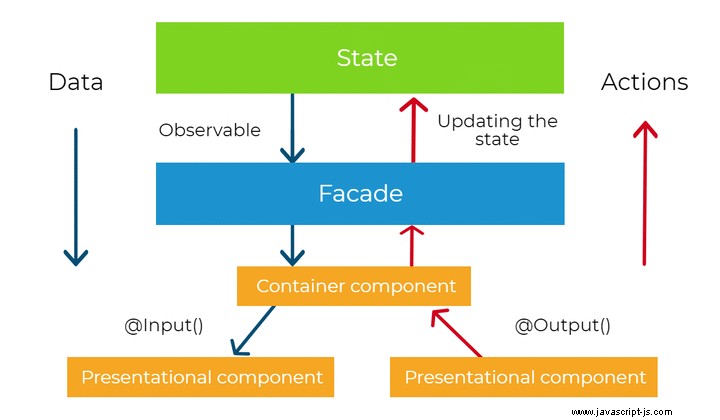
Ogni volta che cambia il valore del modello nella nostra applicazione, il sistema di rilevamento delle modifiche angolari si occupa della propagazione di tale modifica. Lo fa tramite le associazioni di proprietà di input dall'alto verso il basso dell'intero albero dei componenti. Significa che un componente figlio può dipendere solo dal suo genitore e mai viceversa. Questo è il motivo per cui lo chiamiamo flusso di dati unidirezionale. Ciò consente ad Angular di attraversare l'albero dei componenti solo una volta (poiché non ci sono cicli nella struttura ad albero) per ottenere uno stato stabile, il che significa che ogni valore nei collegamenti viene propagato.
Come sappiamo dai capitoli precedenti, c'è il livello principale sopra il livello di presentazione, dove viene implementata la nostra logica applicativa. Ci sono i servizi e i fornitori che operano sui nostri dati. E se applicassimo lo stesso principio di manipolazione dei dati a quel livello? Possiamo posizionare i dati dell'applicazione (lo stato) in un posto "sopra" i componenti e propagare i valori fino ai componenti tramite flussi osservabili (Redux e NgRx chiamano questo luogo un negozio). Lo stato può essere propagato a più componenti e visualizzato in più posizioni, ma mai modificato localmente. Il cambiamento può venire solo "dall'alto" e i componenti sottostanti "riflettono" solo lo stato attuale del sistema. Questo ci fornisce l'importante proprietà del sistema menzionata prima:coerenza dei dati - e l'oggetto dello stato diventa l'unica fonte di verità . In pratica, possiamo visualizzare gli stessi dati in più luoghi e non temere che i valori differiscano.
Il nostro oggetto stato espone i metodi per i servizi nel nostro livello principale per manipolare lo stato. Ogni volta che è necessario modificare lo stato, ciò può avvenire solo chiamando un metodo sull'oggetto stato (o inviando un'azione in caso di utilizzo di NgRx). Quindi, la modifica viene propagata "verso il basso", tramite flussi, al livello di presentazione (o qualsiasi altro servizio). In questo modo, la nostra gestione statale è reattiva . Inoltre, con questo approccio, aumentiamo anche il livello di prevedibilità nel nostro sistema, a causa di rigide regole di manipolazione e condivisione dello stato dell'applicazione. Di seguito puoi trovare un frammento di codice che modella lo stato con BehaviorSubjects.
@Injectable()
export class SettingsState {
private updating$ = new BehaviorSubject<boolean>(false);
private cashflowCategories$ = new BehaviorSubject<CashflowCategory[]>(null);
isUpdating$() {
return this.updating$.asObservable();
}
setUpdating(isUpdating: boolean) {
this.updating$.next(isUpdating);
}
getCashflowCategories$() {
return this.cashflowCategories$.asObservable();
}
setCashflowCategories(categories: CashflowCategory[]) {
this.cashflowCategories$.next(categories);
}
addCashflowCategory(category: CashflowCategory) {
const currentValue = this.cashflowCategories$.getValue();
this.cashflowCategories$.next([...currentValue, category]);
}
updateCashflowCategory(updatedCategory: CashflowCategory) {
const categories = this.cashflowCategories$.getValue();
const indexOfUpdated = categories.findIndex(category => category.id === updatedCategory.id);
categories[indexOfUpdated] = updatedCategory;
this.cashflowCategories$.next([...categories]);
}
updateCashflowCategoryId(categoryToReplace: CashflowCategory, addedCategoryWithId: CashflowCategory) {
const categories = this.cashflowCategories$.getValue();
const updatedCategoryIndex = categories.findIndex(category => category === categoryToReplace);
categories[updatedCategoryIndex] = addedCategoryWithId;
this.cashflowCategories$.next([...categories]);
}
removeCashflowCategory(categoryRemove: CashflowCategory) {
const currentValue = this.cashflowCategories$.getValue();
this.cashflowCategories$.next(currentValue.filter(category => category !== categoryRemove));
}
}
Ricapitoliamo i passaggi per gestire l'interazione dell'utente, tenendo presenti tutti i principi che abbiamo già introdotto. Per prima cosa, immaginiamo che ci sia qualche evento nel livello di presentazione (ad esempio il clic del pulsante). Il componente delega l'esecuzione al livello di astrazione, chiamando il metodo sulla facciata settingsFacade.addCategory() . Quindi, la facciata chiama i metodi sui servizi nel livello principale - categoryApi.create() e settingsState.addCategory() . L'ordine di invocazione di questi due metodi dipende dalla strategia di sincronizzazione che scegliamo (pessimista o ottimista). Infine, lo stato dell'applicazione viene propagato fino al livello di presentazione tramite i flussi osservabili. Questo processo è ben definito .
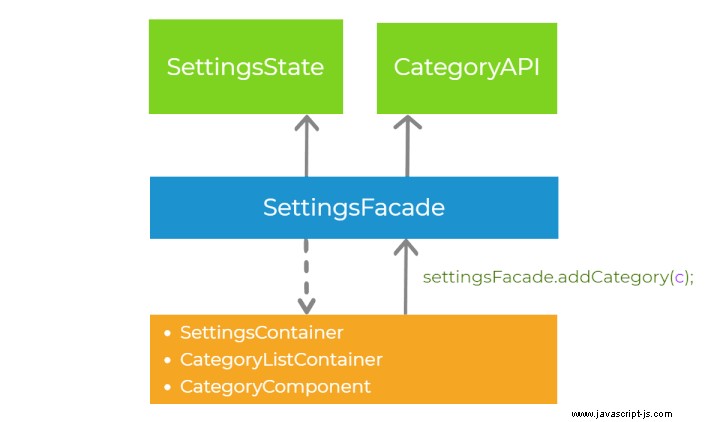
Design modulare
Abbiamo coperto la divisione orizzontale nel nostro sistema e i modelli di comunicazione attraverso di esso. Ora introdurremo una separazione verticale nei moduli di funzionalità. L'idea è di suddividere l'applicazione in moduli di funzionalità che rappresentano diverse funzionalità aziendali. Questo è un altro passo per smontare il sistema in pezzi più piccoli per una migliore manutenibilità. Ciascuno dei moduli delle funzionalità condivide la stessa separazione orizzontale del livello principale, di astrazione e di presentazione. È importante notare che questi moduli potrebbero essere caricati (e precaricati) pigramente nel browser aumentando il tempo di caricamento iniziale dell'applicazione. Di seguito puoi trovare un diagramma che illustra la separazione dei moduli delle caratteristiche.
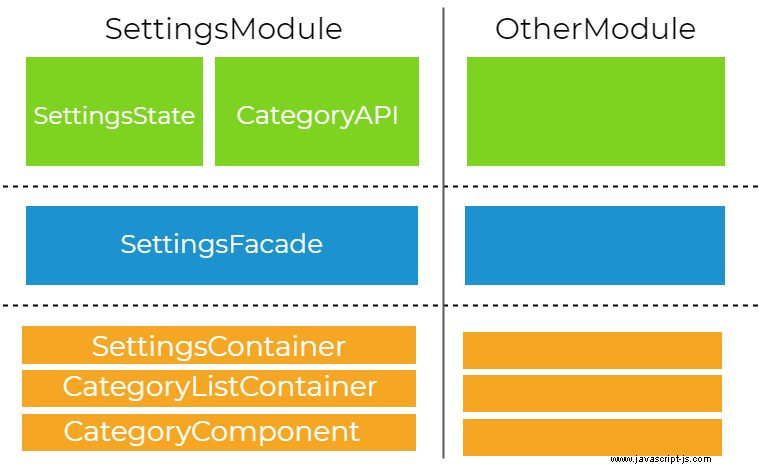
La nostra applicazione ha anche due moduli aggiuntivi per motivi più tecnici. Abbiamo un CoreModule che definisce i nostri servizi singleton, i componenti a istanza singola, la configurazione ed esporta tutti i moduli di terze parti necessari in AppModule . Questo modulo viene importato solo una volta in AppModule . Il secondo modulo è SharedModule che contiene componenti/condutture/direttive comuni ed esporta anche moduli angolari di uso comune (come CommonModule ). SharedModule può essere importato da qualsiasi modulo di funzionalità. Il diagramma seguente presenta la struttura delle importazioni.
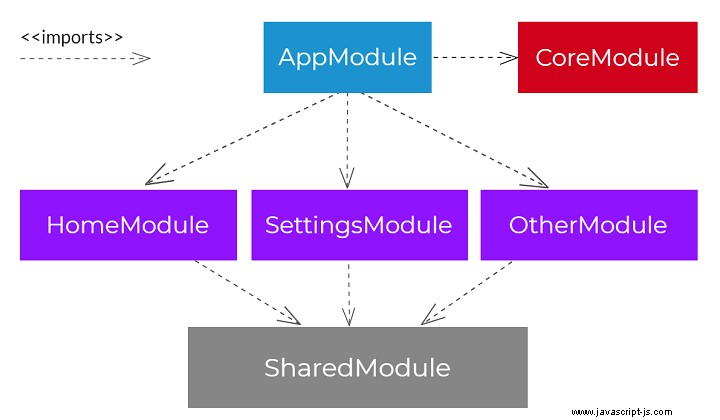
Struttura della directory del modulo
Il diagramma sottostante mostra come possiamo posizionare tutti i pezzi del nostro SettingsModule all'interno delle directory. Possiamo inserire i file all'interno delle cartelle con un nome che ne rappresenti la funzione.

Componenti intelligenti e stupidi
Il modello architettonico finale che introduciamo in questo articolo riguarda i componenti stessi. Vogliamo dividere i componenti in due categorie, a seconda delle loro responsabilità. In primo luogo, ci sono i componenti intelligenti (ovvero contenitori). Questi componenti di solito:
- hanno iniettato/i facciata/e e altri servizi,
- comunicare con il livello centrale,
- passa i dati ai componenti stupidi,
- reagire agli eventi da componenti stupidi,
- sono componenti instradabili di primo livello (ma non sempre!).
Presentato in precedenza CategoriesComponent è intelligente . Ha SettingsFacade iniettato e lo utilizza per comunicare con il livello principale della nostra applicazione.
Nella seconda categoria, ci sono componenti stupidi (aka presentazione). Le loro uniche responsabilità sono presentare l'elemento dell'interfaccia utente e delegare l'interazione dell'utente "fino" ai componenti intelligenti tramite eventi. Pensa a un elemento HTML nativo come <button>Click me</button> . Quell'elemento non ha alcuna logica particolare implementata. Possiamo pensare al testo "Fai clic su di me" come input per questo componente. Ha anche alcuni eventi a cui è possibile iscriversi, come l'evento clic. Di seguito puoi trovare uno snippet di codice di una semplice presentazione componente con un input e nessun evento di output.
@Component({
selector: 'budget-progress',
templateUrl: './budget-progress.component.html',
styleUrls: ['./budget-progress.component.scss'],
changeDetection: ChangeDetectionStrategy.OnPush
})
export class BudgetProgressComponent {
@Input()
budget: Budget;
today: string;
}
Riepilogo
Abbiamo coperto un paio di idee su come progettare l'architettura di un'applicazione Angular. Questi principi, se applicati con saggezza, possono aiutare a mantenere una velocità di sviluppo sostenibile nel tempo e consentire la facile distribuzione di nuove funzionalità. Per favore, non trattarle come regole rigide, ma piuttosto come raccomandazioni che potrebbero essere utilizzate quando hanno senso.
Abbiamo esaminato da vicino i livelli di astrazione, il flusso di dati unidirezionale e la gestione dello stato reattivo, il design modulare e il modello di componenti intelligenti/stupidi. Spero che questi concetti possano essere utili nei vostri progetti e, come sempre, se avete domande, sono più che felice di chattare con voi.
A questo punto, vorrei fare un enorme complimento a Brecht Billiet che ha scritto questo post sul blog, che mi ha introdotto all'idea di Abstraction Layer e Facade. Grazie, Brecht! Un grande grazie va anche a Tomek Sułkowski che ha esaminato la mia prospettiva su un'architettura a strati.