En este tutorial vamos a experimentar con Web Speech API. Es una interfaz de navegador muy poderosa que le permite grabar el habla humana y convertirla en texto. También lo usaremos para hacer lo contrario:leer cadenas con una voz humana.
¡Entremos de inmediato!
La aplicación
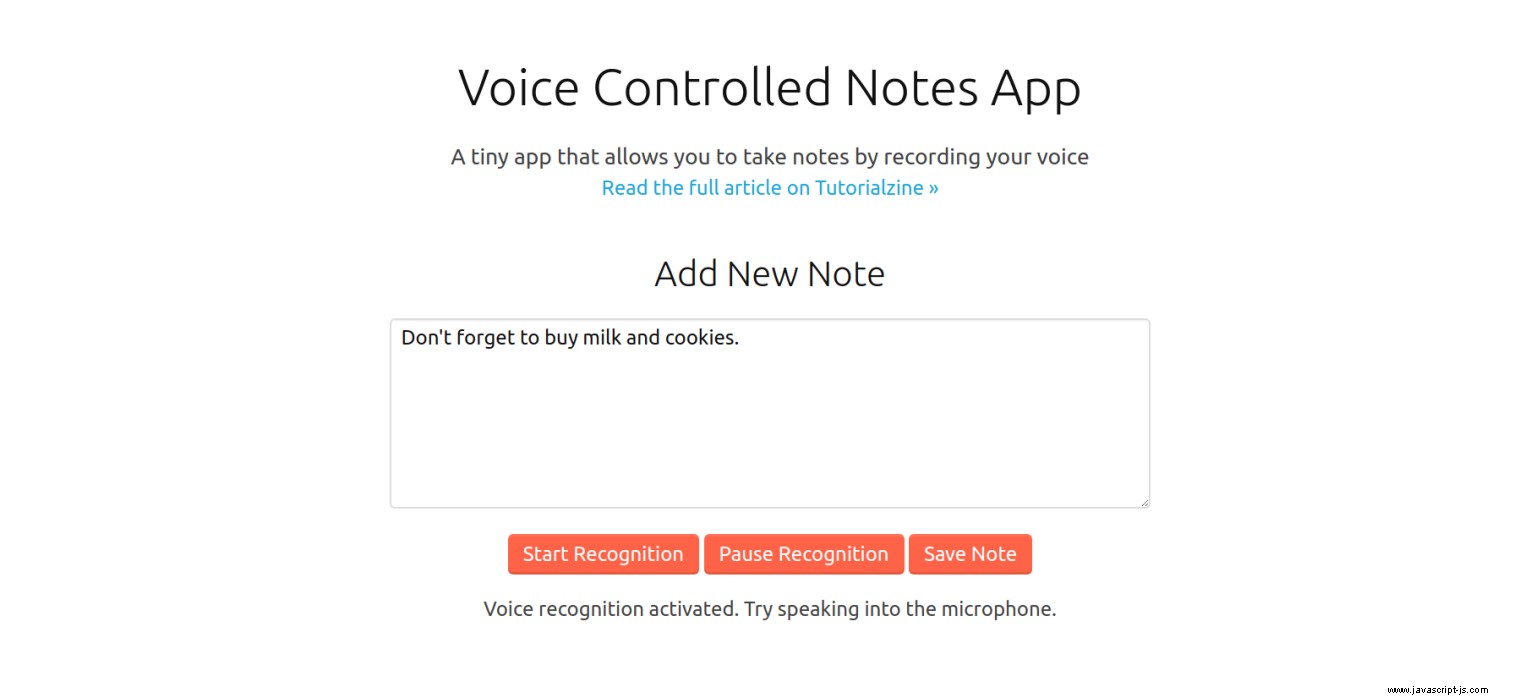
Para mostrar la capacidad de la API, vamos a crear una aplicación de notas simple impulsada por voz. Hace 3 cosas:
- Toma notas usando voz a texto o entrada de teclado tradicional.
- Guarda las notas en localStorage.
- Muestra todas las notas y ofrece la opción de escucharlas a través de Speech Synthesis.
No usaremos dependencias sofisticadas, solo jQuery antiguo para operaciones DOM más sencillas y Shoelace para estilos CSS. Vamos a incluirlos directamente a través de CDN, no es necesario que NPM se involucre en un proyecto tan pequeño.
El HTML y el CSS son bastante estándar, por lo que los omitiremos e iremos directamente al JavaScript. Para ver el código fuente completo, vaya a Descargar cerca de la parte superior de la página.
Voz a texto
La Web Speech API en realidad está separada en dos interfaces totalmente independientes. Tenemos SpeechRecognition para comprender la voz humana y convertirla en texto (Habla -> Texto) y SpeechSynthesis para leer cadenas en voz alta en una voz generada por computadora (Texto -> Habla). Empezaremos con el primero.
La API de reconocimiento de voz es sorprendentemente precisa para una función de navegador gratuita. Reconoció correctamente casi todo mi discurso y sabía qué palabras van juntas para formar frases que tienen sentido. También le permite dictar caracteres especiales como puntos, signos de interrogación y líneas nuevas.
Lo primero que debemos hacer es verificar si el usuario tiene acceso a la API y mostrar un mensaje de error apropiado. Desafortunadamente, la API de voz a texto solo es compatible con Chrome y Firefox (con una bandera), por lo que muchas personas probablemente verán ese mensaje.
try {
var SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
var recognition = new SpeechRecognition();
}
catch(e) {
console.error(e);
$('.no-browser-support').show();
$('.app').hide();
}
El recognition variable nos dará acceso a todos los métodos y propiedades de la API. Hay varias opciones disponibles, pero solo estableceremos recognition.continuous a la verdad Esto permitirá a los usuarios hablar con pausas más largas entre palabras y frases.
Antes de que podamos usar el reconocimiento de voz, también tenemos que configurar un par de controladores de eventos. La mayoría de ellos simplemente escuchan los cambios en el estado de reconocimiento:
recognition.onstart = function() {
instructions.text('Voice recognition activated. Try speaking into the microphone.');
}
recognition.onspeechend = function() {
instructions.text('You were quiet for a while so voice recognition turned itself off.');
}
recognition.onerror = function(event) {
if(event.error == 'no-speech') {
instructions.text('No speech was detected. Try again.');
};
}
Sin embargo, hay un onresult especial evento que es muy crucial. Se ejecuta cada vez que el usuario pronuncia una o varias palabras en rápida sucesión, dándonos acceso a una transcripción de texto de lo dicho.
Cuando capturamos algo con el onresult handler lo guardamos en una variable global y lo mostramos en un área de texto:
recognition.onresult = function(event) {
// event is a SpeechRecognitionEvent object.
// It holds all the lines we have captured so far.
// We only need the current one.
var current = event.resultIndex;
// Get a transcript of what was said.
var transcript = event.results[current][0].transcript;
// Add the current transcript to the contents of our Note.
noteContent += transcript;
noteTextarea.val(noteContent);
} El código anterior está ligeramente simplificado. Hay un error muy extraño en los dispositivos Android que hace que todo se repita dos veces. Todavía no hay una solución oficial, pero logramos resolver el problema sin efectos secundarios obvios. Con ese error en mente, el código se ve así:
var mobileRepeatBug = (current == 1 && transcript == event.results[0][0].transcript);
if(!mobileRepeatBug) {
noteContent += transcript;
noteTextarea.val(noteContent);
}
Una vez que tengamos todo configurado, podemos comenzar a usar la función de reconocimiento de voz del navegador. Para iniciarlo simplemente llame al start() método:
$('#start-record-btn').on('click', function(e) {
recognition.start();
}); Esto pedirá a los usuarios que den permiso. Si se otorga, se activará el micrófono del dispositivo.
El navegador escuchará durante un rato y se transcribirá cada frase o palabra reconocida. La API dejará de escuchar automáticamente después de un par de segundos de silencio o cuando se detenga manualmente.
$('#pause-record-btn').on('click', function(e) {
recognition.stop();
}); ¡Con esto, la parte de voz a texto de nuestra aplicación está completa! Ahora, ¡hagamos lo contrario!
Texto a voz
Speech Synthesys es realmente muy fácil. Se puede acceder a la API a través del objeto SpeechSynthesis y hay un par de métodos para reproducir, pausar y otras cosas relacionadas con el audio. También tiene un par de opciones geniales que cambian el tono, la velocidad e incluso la voz del lector.
Todo lo que realmente necesitaremos para nuestra demostración es el speak() método. Espera un argumento, una instancia del bellamente llamado SpeechSynthesisUtterance clase.
Aquí está el código completo necesario para leer una cadena.
function readOutLoud(message) {
var speech = new SpeechSynthesisUtterance();
// Set the text and voice attributes.
speech.text = message;
speech.volume = 1;
speech.rate = 1;
speech.pitch = 1;
window.speechSynthesis.speak(speech);
} Cuando se llama a esta función, una voz de robot leerá la cadena dada, dando la mejor impresión humana.
Conclusión
En una era en la que los asistentes de voz son más populares que nunca, una API como esta le brinda un atajo rápido para crear bots que entiendan y hablen el lenguaje humano.
Agregar control de voz a sus aplicaciones también puede ser una excelente forma de mejorar la accesibilidad. Los usuarios con discapacidad visual pueden beneficiarse de las interfaces de usuario de voz a texto y de texto a voz.
Las API de síntesis de voz y reconocimiento de voz funcionan bastante bien y manejan diferentes idiomas y acentos con facilidad. Lamentablemente, tienen soporte de navegador limitado por ahora, lo que reduce su uso en producción. Si necesita una forma más confiable de reconocimiento de voz, eche un vistazo a estas API de terceros:
- API de voz de Google Cloud
- API de voz de Bing
- CMUSphinx y su versión de JavaScript Pocketsphinx (ambos de código abierto).
- API.AI:API gratuita de Google con tecnología de aprendizaje automático