Este ensayo se inspiró en la serie de libros de Kyle Simpson, No sabes JavaScript . Son un buen comienzo con los fundamentos de JavaScript. Node es principalmente JavaScript, excepto por algunas diferencias que resaltaré en este ensayo. El código está en el Nodo que no conoces Repositorio de GitHub bajo el code carpeta.
¿Por qué preocuparse por Node? ¡Node es JavaScript y JavaScript está en casi todas partes! ¿Qué pasa si el mundo puede ser un lugar mejor si más desarrolladores dominan Node? ¡Mejores aplicaciones equivalen a una vida mejor!
Este es un fregadero de cocina de las características básicas subjetivamente más interesantes. Los puntos clave de este ensayo son:
- Bucle de eventos:repaso del concepto central que permite E/S sin bloqueo
- Global y proceso:cómo acceder a más información
- Emisores de eventos:curso acelerado en el patrón basado en eventos
- Flujos y búferes:forma efectiva de trabajar con datos
- Clusters:Fork procesa como un profesional
- Manejo de errores asincrónicos:AsyncWrap, Domain y uncaughtException
- Complementos de C++:contribuir al núcleo y escribir sus propios complementos de C++
Bucle de eventos
Podemos comenzar con el ciclo de eventos que es el núcleo de Node.
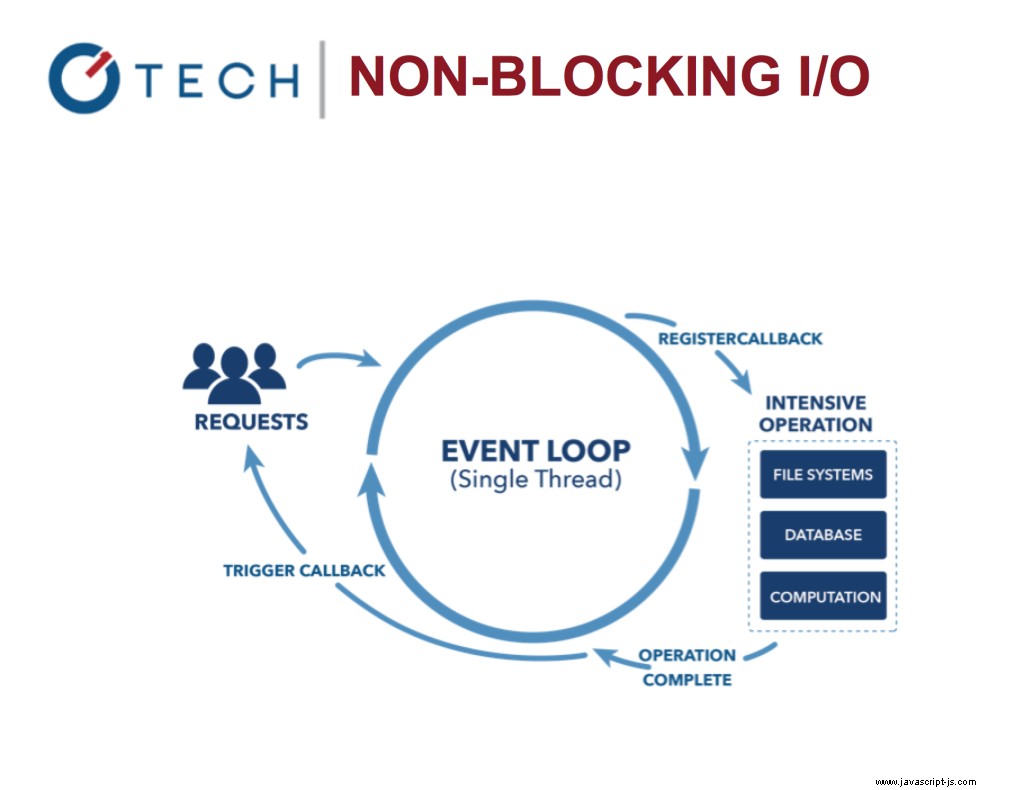
E/S sin bloqueo de Node.js
Permite el procesamiento de otras tareas mientras las llamadas IO están en proceso. Piense en Nginx frente a Apache. ¡Permite que Node sea muy rápido y eficiente porque el bloqueo de E/S es costoso!
Mira este ejemplo básico de un println retrasado función en Java:
System.out.println("Step: 1");
System.out.println("Step: 2");
Thread.sleep(1000);
System.out.println("Step: 3");
Es comparable (pero no realmente) a este código de Nodo:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
}, 1000)
console.log('Step: 2')
Sin embargo, no es lo mismo. Tienes que empezar a pensar de forma asíncrona. La salida del script de Node es 1, 2, 3, pero si tuviéramos más declaraciones después del "Paso 2", se habrían ejecutado antes de la devolución de llamada de setTimeout . Mira este fragmento:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
console.log('Step 5')
}, 1000);
console.log('Step: 2')
console.log('Step 4')
Produce 1, 2, 4, 3, 5. Esto se debe a que setTimeout pone su devolución de llamada en los ciclos futuros del bucle de eventos.
Piense en el bucle de eventos como siempre girando como un for o un while círculo. Solo se detiene si no hay nada que ejecutar ahora o en el futuro.
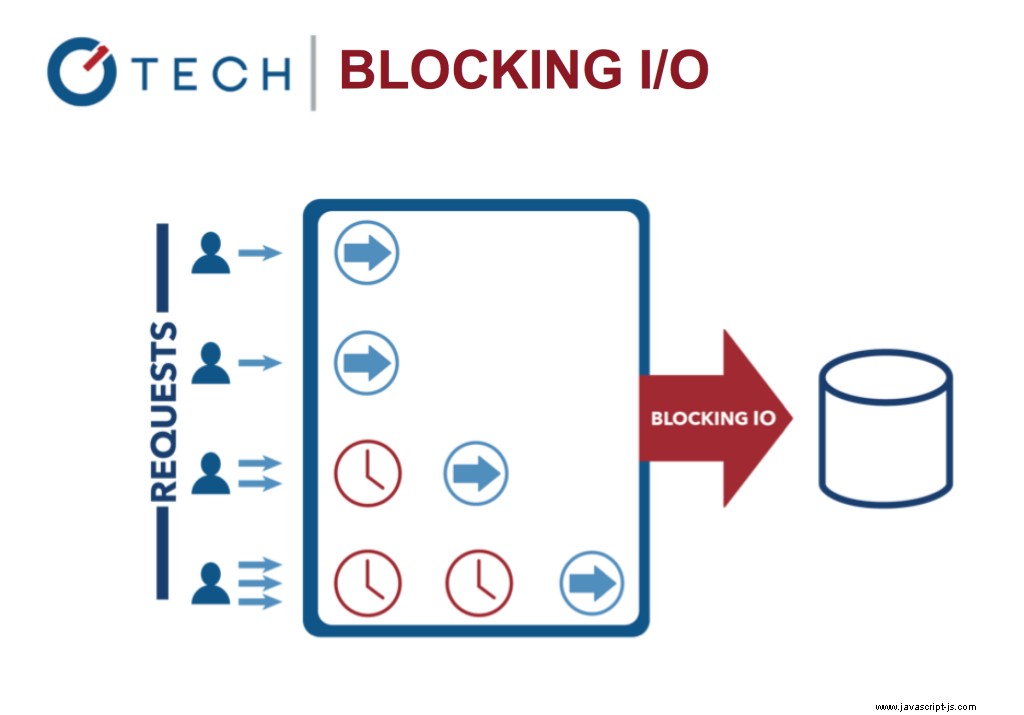
Bloqueo de E/S:subprocesamiento múltiple de Java
El ciclo de eventos permite que los sistemas sean más efectivos porque ahora puede hacer más cosas mientras espera que termine su costosa tarea de entrada/salida.
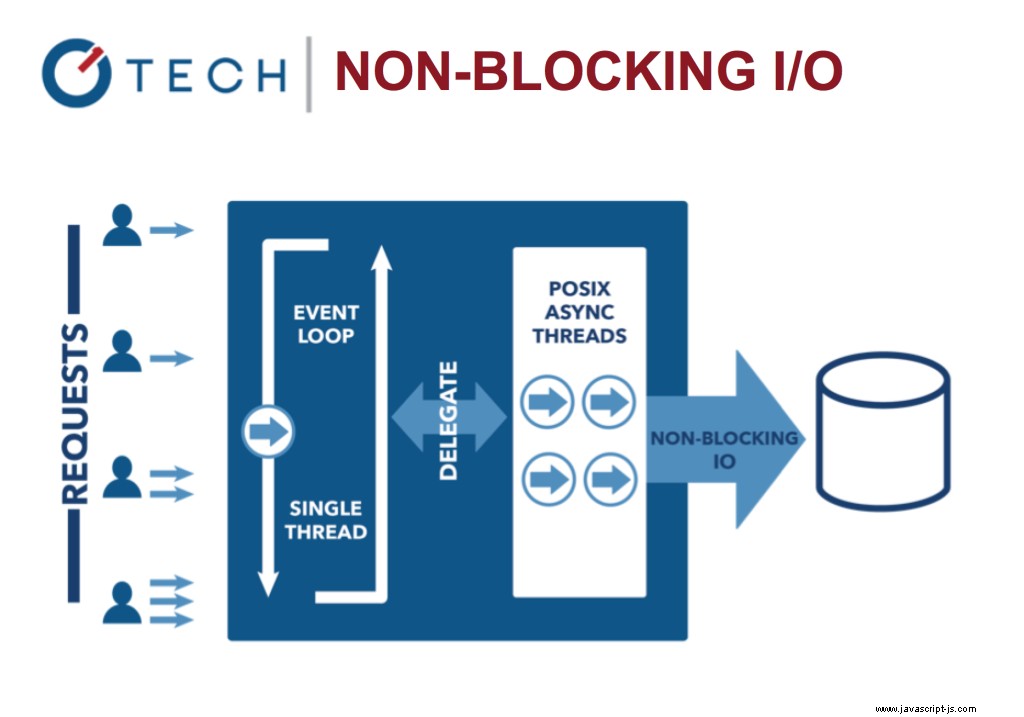
E/S sin bloqueo:Node.js
Esto contrasta con el modelo de concurrencia más común de hoy en día donde se emplean subprocesos del sistema operativo. Las redes basadas en subprocesos son relativamente ineficientes y muy difíciles de usar. Además, los usuarios de Node no tienen que preocuparse por bloquear el proceso, no hay bloqueos.
Una nota al margen rápida:todavía es posible escribir código de bloqueo en Node.js. ? Considere este código simple pero bloqueador de Node.js:
console.log('Step: 1')
var start = Date.now()
for (var i = 1; i<1000000000; i++) {
// This will take 100-1000ms depending on your machine
}
var end = Date.now()
console.log('Step: 2')
console.log(end-start)
Por supuesto, la mayoría de las veces no tenemos bucles vacíos en nuestro código. Detectar código síncrono y, por lo tanto, de bloqueo puede ser más difícil cuando se utilizan módulos de otras personas. Por ejemplo, núcleo fs (sistema de archivos) viene con dos conjuntos de métodos. Cada par realiza las mismas funciones pero de forma diferente. Hay bloqueos fs Métodos de Node.js que tienen la palabra Sync en sus nombres:
[Nota al margen]
Leer publicaciones de blog es bueno, pero ver cursos en video es aún mejor porque son más atractivos.
Muchos desarrolladores se quejaron de la falta de material de video de calidad asequible en Node. Es una distracción ver videos de YouTube y una locura pagar $ 500 por un curso de video de Node.
Visite Node University, que tiene cursos de video GRATUITOS en Node:node.university.
[Fin de la nota al margen]
var fs = require('fs')
var contents = fs.readFileSync('accounts.txt','utf8')
console.log(contents)
console.log('Hello Ruby\n')
var contents = fs.readFileSync('ips.txt','utf8')
console.log(contents)
console.log('Hello Node!')
Los resultados son muy predecibles incluso para personas nuevas en Node/JavaScript:
data1->Hello Ruby->data2->Hello NODE!
Las cosas cambian cuando cambiamos a métodos asincrónicos. Este es un código Node.js que no bloquea:
var fs = require('fs');
var contents = fs.readFile('accounts.txt','utf8', function(err,contents){
console.log(contents);
});
console.log('Hello Python\n');
var contents = fs.readFile('ips.txt','utf8', function(err,contents){
console.log(contents);
});
console.log("Hello Node!");
Imprime los contenidos al final porque tardarán un tiempo en ejecutarse, están en las devoluciones de llamada. Los bucles de eventos llegarán a ellos cuando finalice la lectura del archivo:
Hello Python->Hello Node->data1->data2
Por lo tanto, el bucle de eventos y la E/S sin bloqueo son muy potentes, pero es necesario codificar de forma asíncrona, que no es la forma en que la mayoría de nosotros aprendimos a codificar en las escuelas.
Global
Al cambiar a Node.js desde el navegador JavaScript u otro lenguaje de programación, surgen estas preguntas:
- ¿Dónde guardar las contraseñas?
- Cómo crear variables globales (no
windowen el nodo)? - ¿Cómo acceder a la entrada CLI, SO, plataforma, uso de memoria, versiones, etc.?
Hay un objeto global. Tiene ciertas propiedades. Algunos de ellos son los siguientes:
global.process:Proceso, sistema, información del entorno (puede acceder a la entrada CLI, variables de entorno con contraseñas, memoria, etc.)global.__filename:nombre de archivo y ruta al script que se está ejecutando actualmente donde se encuentra esta instrucciónglobal.__dirname:ruta absoluta al script que se está ejecutando actualmenteglobal.module:Objeto para exportar código haciendo de este archivo un móduloglobal.require():Método para importar módulos, archivos JSON y carpetas
Luego, tenemos los sospechosos habituales, métodos del navegador JavaScript:
global.console()global.setInterval()global.setTimeout()
Se puede acceder a cada una de las propiedades globales con el nombre en mayúscula GLOBAL o sin el espacio de nombres, por ejemplo, process en lugar de global.process .
Proceso
El objeto de proceso tiene mucha información, por lo que merece su propia sección. Enumeraré solo algunas de las propiedades:
process.pid:ID de proceso de esta instancia de nodoprocess.versions:Varias versiones de Node, V8 y otros componentesprocess.arch:Arquitectura del sistemaprocess.argv:argumentos CLIprocess.env:Variables de entorno
Algunos de los métodos son los siguientes:
process.uptime():Obtener tiempo de actividadprocess.memoryUsage():Obtener uso de memoriaprocess.cwd():Obtener el directorio de trabajo actual. No confundir con__dirnameque no depende de la ubicación desde la que se haya iniciado el proceso.process.exit():Salir del proceso actual. Puede pasar un código como 0 o 1.process.on():Adjunte un detector de eventos, por ejemplo, `on('uncaughtException')
Pregunta difícil:¿A quién le gustan y entiende las devoluciones de llamadas? ?
Algunas personas aman demasiado las devoluciones de llamada, por lo que crearon http://callbackhell.com. Si aún no está familiarizado con este término, aquí tiene una ilustración:
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
Callback hell es difícil de leer y es propenso a errores. ¿Cómo modularizamos y organizamos el código asíncrono, además de las devoluciones de llamada que no son muy escalables desde el punto de vista del desarrollo?
Emisores de eventos
Para ayudar con el infierno de devolución de llamada o la pirámide de la perdición, existen emisores de eventos. Permiten implementar tu código asíncrono con eventos.
En pocas palabras, el emisor de eventos es algo que desencadena un evento que cualquiera puede escuchar. En node.js, un evento se puede describir como una cadena con una devolución de llamada correspondiente.
Los emisores de eventos tienen estos propósitos:
- El manejo de eventos en Node usa el patrón de observador
- Un evento, o asunto, realiza un seguimiento de todas las funciones asociadas con él
- Estas funciones asociadas, conocidas como observadores, se ejecutan cuando se activa el evento dado
Para usar emisores de eventos, importe el módulo e instancia el objeto:
var events = require('events')
var emitter = new events.EventEmitter()
Después de eso, puede adjuntar detectores de eventos y desencadenar/emitir eventos:
emitter.on('knock', function() {
console.log('Who\'s there?')
})
emitter.on('knock', function() {
console.log('Go away!')
})
emitter.emit('knock')
Hagamos algo más útil con EventEmitter al heredar de ella. Imagine que tiene la tarea de implementar una clase para realizar trabajos de correo electrónico mensuales, semanales y diarios. La clase debe ser lo suficientemente flexible para que los desarrolladores personalicen el resultado final. En otras palabras, quienquiera que consuma esta clase debe poder poner alguna lógica personalizada cuando termine el trabajo.
El siguiente diagrama explica lo que heredamos del módulo de eventos para crear Job y luego usa done detector de eventos para personalizar el comportamiento del Job clase:

Emisores de eventos de Node.js:patrón de observador
La clase Job conservará sus propiedades, pero también obtendrá eventos. Todo lo que necesitamos es activar el done cuando termina el proceso:
// job.js
var util = require('util')
var Job = function Job() {
var job = this
// ...
job.process = function() {
// ...
job.emit('done', { completedOn: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter)
module.exports = Job
Ahora, nuestro objetivo es personalizar el comportamiento de Job al final de la tarea. Porque emite done , podemos adjuntar un detector de eventos:
// weekly.js
var Job = require('./job.js')
var job = new Job()
job.on('done', function(details){
console.log('Job was completed at', details.completedOn)
job.removeAllListeners()
})
job.process()
Hay más funciones para los emisores:
emitter.listeners(eventName):enumera todos los detectores de eventos para un evento determinadoemitter.once(eventName, listener):adjunte un detector de eventos que se active solo una vez.emitter.removeListener(eventName, listener):eliminar un detector de eventos.
El patrón de eventos se usa en todo Node y especialmente en sus módulos principales. Por esta razón, dominar los eventos le dará un gran valor por su tiempo.
Transmisiones
Hay algunos problemas cuando se trabaja con datos de gran tamaño en Node. La velocidad puede ser lenta y el límite del búfer es de ~1 Gb. Además, ¿cómo funciona si el recurso es continuo, nunca fue diseñado para terminar? Para superar estos problemas, utilice secuencias.
Los flujos de nodos son abstracciones para la fragmentación continua de datos. En otras palabras, no hay necesidad de esperar a que se cargue todo el recurso. Eche un vistazo al siguiente diagrama que muestra el enfoque estándar con búfer:

Enfoque de búfer de Node.js
Tenemos que esperar a que se cargue todo el búfer antes de que podamos comenzar a procesar y/o generar. Ahora, compáralo con el siguiente diagrama que representa arroyos. En él, podemos procesar datos y/o generarlos de inmediato, desde el primer fragmento:

Enfoque de transmisión de Node.js
Tiene cuatro tipos de Streams en Node:
- Legible:puede leer de ellos
- Escribible:puedes escribirles
- Dúplex:puede leer y escribir
- Transformar:los usa para transformar datos
Los flujos están prácticamente en todas partes en Node. Las implementaciones de secuencias más utilizadas son:
- Solicitudes y respuestas HTTP
- Entrada/salida estándar
- El archivo lee y escribe
Los flujos se heredan del objeto Emisor de eventos para proporcionar un patrón de observador, es decir, eventos. ¿Recuerdalos? Podemos usar esto para implementar flujos.
Ejemplo de transmisión legible
Un ejemplo de flujo legible sería process.stdin que es un flujo de entrada estándar. Contiene datos que entran en una aplicación. La entrada generalmente proviene del teclado utilizado para iniciar el proceso.
Para leer datos de stdin , usa el data y end eventos. El data la devolución de llamada del evento tendrá chunk como su argumento:
process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})
Así que chunk luego se introduce como entrada en el programa. Según el tamaño de la entrada, este evento puede activarse varias veces. Un end El evento es necesario para señalar la conclusión del flujo de entrada.
Nota:stdin está en pausa de forma predeterminada y debe reanudarse antes de que se puedan leer los datos.
Las secuencias legibles también tienen read() Interfaz que funciona sincrónicamente. Devuelve chunk o null cuando la corriente ha terminado. Podemos usar este comportamiento y poner null !== (chunk = readable.read()) en el while condición:
var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})
Idealmente, queremos escribir código asíncrono en Node tanto como sea posible para evitar bloquear el hilo. Sin embargo, los fragmentos de datos son pequeños, por lo que no nos preocupamos por bloquear el hilo con readable.read() síncrono. .
Ejemplo de flujo de escritura
Un ejemplo de flujo de escritura es process.stdout . Los flujos de salida estándar contienen datos que salen de una aplicación. Los desarrolladores pueden escribir en la transmisión con el write operación.
process.stdout.write('A simple message\n')
Los datos escritos en la salida estándar son visibles en la línea de comando al igual que cuando usamos console.log() .
Tubo
Node proporciona a los desarrolladores una alternativa a los eventos. Podemos usar pipe() método. Este ejemplo lee un archivo, lo comprime con GZip y escribe los datos comprimidos en un archivo:
var r = fs.createReadStream('file.txt')
var z = zlib.createGzip()
var w = fs.createWriteStream('file.txt.gz')
r.pipe(z).pipe(w)
Readable.pipe() toma un flujo grabable y devuelve el destino, por lo tanto, podemos encadenar pipe() métodos uno tras otro.
Por lo tanto, puede elegir entre eventos y canalizaciones cuando utiliza secuencias.
Transmisiones HTTP
La mayoría de nosotros usamos Node para crear aplicaciones web tradicionales (piense en servidor) o RESTful APi (piense en cliente). Entonces, ¿qué pasa con una solicitud HTTP? ¿Podemos transmitirlo? La respuesta es un rotundo sí .
La solicitud y la respuesta son flujos legibles y escribibles y se heredan de los emisores de eventos. Podemos adjuntar un data oyente de eventos En su devolución de llamada, recibiremos chunk , podemos transformarlo de inmediato sin esperar la respuesta completa. En este ejemplo, estoy concatenando el body y analizándolo en la devolución de llamada del end evento:
const http = require('http')
var server = http.createServer( (req, res) => {
var body = ''
req.setEncoding('utf8')
req.on('data', (chunk) => {
body += chunk
})
req.on('end', () => {
var data = JSON.parse(body)
res.write(typeof data)
res.end()
})
})
server.listen(1337)
Nota:()=>{} es la sintaxis de ES6 para las funciones de flecha gruesa, mientras que const es un nuevo operador. Si aún no está familiarizado con las características y la sintaxis de ES6/ES2015, consulte el artículo
Las 10 características principales de ES6 que todo desarrollador de JavaScript ocupado debe conocer .
Ahora hagamos que nuestro servidor se parezca un poco más a un ejemplo de la vida real usando Express.js. En el siguiente ejemplo, tengo una imagen enorme (~8 Mb) y dos conjuntos de rutas Express:/stream y /non-stream .
flujo-servidor.js:
app.get('/non-stream', function(req, res) {
var file = fs.readFile(largeImagePath, function(error, data){
res.end(data)
})
})
app.get('/stream', function(req, res) {
var stream = fs.createReadStream(largeImagePath)
stream.pipe(res)
})
También tengo una implementación alternativa con eventos en /stream2 e implementación síncrona en /non-stream2 . Hacen lo mismo cuando se trata de transmisión o no transmisión, pero con una sintaxis y un estilo diferentes. Los métodos sincrónicos en este caso son más eficaces porque solo enviamos una solicitud, no solicitudes simultáneas.
Para iniciar el ejemplo, ejecute en su terminal:
$ node server-stream
Luego abra http://localhost:3000/stream y http://localhost:3000/non-stream en Chrome. La pestaña Red en DevTools le mostrará los encabezados. Comparar X-Response-Time . En mi caso, fue un orden de magnitud menor para /stream y /stream2 :300ms contra 3–5 s.
Su resultado variará, pero la idea es que con la transmisión, los usuarios/clientes comenzarán a obtener datos antes. ¡Los flujos de nodos son realmente poderosos! Hay algunos buenos recursos de transmisión para dominarlos y convertirse en un experto en transmisiones en su equipo.
[Stream Handbook](https://github.com/substack/stream-handbook] y stream-adventure que puede instalar con npm:
$ sudo npm install -g stream-adventure
$ stream-adventure
Búferes
¿Qué tipo de datos podemos usar para datos binarios? Si recuerda, el JavaScript del navegador no tiene un tipo de datos binarios, pero Node sí. Se llama tampón. Es un objeto global, por lo que no necesitamos importarlo como módulo.
Para crear un tipo de datos binarios, use una de las siguientes declaraciones:
Buffer.alloc(size)Buffer.from(array)Buffer.from(buffer)Buffer.from(str[, encoding])
Los documentos oficiales de Buffer enumeran todos los métodos y codificaciones. La codificación más popular es utf8 .
Un búfer típico se verá como un galimatías, por lo que debemos convertirlo en una cadena con toString() tener un formato legible por humanos. El for loop creará un búfer con un alfabeto:
let buf = Buffer.alloc(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97 // 97 is ASCII a
}
El búfer se verá como una matriz de números si no lo convertimos en una cadena:
console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
Y podemos usar toString para convertir el búfer en una cadena.
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz
El método toma un número inicial y posiciones finales si solo necesitamos una subcadena:
buf.toString('ascii', 0, 5) // outputs: abcde
buf.toString('utf8', 0, 5) // outputs: abcde
buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcde
¿Recuerdas fs? Por defecto el data el valor también es búfer:
fs.readFile('/etc/passwd', function (err, data) {
if (err) return console.error(err)
console.log(data)
});
data es un búfer cuando se trabaja con archivos.
Clústeres
Es posible que a menudo escuche un argumento de los escépticos de Node de que es de un solo subproceso, por lo tanto, no escalará. Hay un módulo central cluster (lo que significa que no necesita instalarlo; es parte de la plataforma), lo que le permite utilizar toda la potencia de la CPU de cada máquina. Esto le permitirá escalar los programas de Node verticalmente.
El código es muy fácil. Necesitamos importar el módulo, crear un maestro y varios trabajadores. Por lo general, creamos tantos procesos como la cantidad de CPU que tenemos. No es una regla escrita en piedra. Puede tener tantos procesos nuevos como desee, pero en un momento dado se activa la ley de los rendimientos decrecientes y no obtendrá ninguna mejora en el rendimiento.
El código para maestro y trabajador está en el mismo archivo. El trabajador puede escuchar en el mismo puerto y enviar un mensaje (a través de eventos) al maestro. El maestro puede escuchar los eventos y reiniciar los clústeres según sea necesario. La forma de escribir código para maestro es usar cluster.isMaster() , y para el trabajador es cluster.isWorker() . La mayor parte del servidor, el código del servidor residirá en el trabajador (isWorker() ).
// cluster.js
var cluster = require('cluster')
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
// your server code
})
En el cluster.js ejemplo, mi servidor genera ID de proceso, por lo que puede ver que diferentes trabajadores manejan diferentes solicitudes. Es como un balanceador de carga, pero no es un verdadero balanceador de carga porque las cargas no se distribuirán de manera uniforme. Es posible que vea muchas más solicitudes en un solo proceso (el PID será el mismo).
Para ver que diferentes trabajadores atienden diferentes solicitudes, use loadtest que es una herramienta de prueba de estrés (o carga) basada en nodos:
- Instalar
loadtestcon npm:$ npm install -g loadtest - Ejecute
code/cluster.jscon nodo ($ node cluster.js); dejar el servidor funcionando - Ejecutar pruebas de carga con:
$ loadtest http://localhost:3000 -t 20 -c 10en una nueva ventana - Analice los resultados tanto en la terminal del servidor como en el
loadtestterminal - Presiona control+c en la terminal del servidor cuando termine la prueba. Debería ver diferentes PID. Anote el número de solicitudes atendidas.
El -t 20 -c 10 en el loadtest comando significa que habrá 10 solicitudes simultáneas y el tiempo máximo es de 20 segundos.
El clúster central es parte del núcleo y esa es prácticamente su única ventaja. Cuando esté listo para implementar en producción, es posible que desee utilizar un administrador de procesos más avanzado:
strong-cluster-control(https://github.com/strongloop/strong-cluster-control), o$ slc run:buena elecciónpm2(https://github.com/Unitech/pm2):buena elección
pm2
Cubrimos el pm2 herramienta que es una de las formas de escalar su aplicación Node verticalmente (una de las mejores formas), además de tener un rendimiento y características de nivel de producción.
En pocas palabras, pm2 tiene estas ventajas:
- Equilibrador de carga y otras características
- Tiempo de inactividad de recarga de 0, es decir, siempre vivo
- Buena cobertura de prueba
Puede encontrar documentos de pm2 en https://github.com/Unitech/pm2 y http://pm2.keymetrics.io.
Eche un vistazo a este servidor Express (server.js ) como el ejemplo de pm2. No hay código repetitivo isMaster() lo cual es bueno porque no necesitas modificar tu código fuente como hicimos con cluster . Todo lo que hacemos en este servidor es logpid y mantén estadísticas sobre ellos.
var express = require('express')
var port = 3000
global.stats = {}
console.log('worker (%s) is now listening to http://localhost:%s',
process.pid, port)
var app = express()
app.get('*', function(req, res) {
if (!global.stats[process.pid]) global.stats[process.pid] = 1
else global.stats[process.pid] += 1;
var l ='cluser '
+ process.pid
+ ' responded \n';
console.log(l, global.stats)
res.status(200).send(l)
})
app.listen(port)
Para lanzar este pm2 ejemplo, use pm2 start server.js . Puede pasar el número de instancias/procesos para generar (-i 0 significa tantas como la cantidad de CPU, que es 4 en mi caso) y la opción de iniciar sesión en un archivo (-l log.txt ):
$ pm2 start server.js -i 0 -l ./log.txt

Otra cosa buena de pm2 es que pasa a primer plano. Para ver lo que se está ejecutando actualmente, ejecute:
$ pm2 list
Luego, utilice loadtest como hicimos en el núcleo cluster ejemplo. En una nueva ventana, ejecute estos comandos:
$ loadtest http://localhost:3000 -t 20 -c 10
Sus resultados pueden variar, pero obtengo resultados distribuidos más o menos uniformemente en log.txt :
cluser 67415 responded
{ '67415': 4078 }
cluser 67430 responded
{ '67430': 4155 }
cluser 67404 responded
{ '67404': 4075 }
cluser 67403 responded
{ '67403': 4054 }
Aparición vs Bifurcación vs Ejecutivo
Ya que hemos usado fork() en el cluter.js ejemplo para crear nuevas instancias de servidores Node, vale la pena mencionar que hay tres formas de iniciar un proceso externo desde dentro de Node.js. Son spawn() , fork() y exec() , y los tres provienen del núcleo child_process módulo. Las diferencias se pueden resumir en la siguiente lista:
require('child_process').spawn():se usa para datos de gran tamaño, admite flujos, se puede usar con cualquier comando y no crea una nueva instancia V8require('child_process').fork()– Crea una nueva instancia V8, instancia múltiples trabajadores y funciona solo con scripts de Node.js (nodecomando)require('child_process').exec()– Utiliza un búfer que lo hace inadecuado para grandes datos o transmisión, funciona de manera asíncrona para obtener todos los datos a la vez en la devolución de llamada y se puede usar con cualquier comando, no solonode
Echemos un vistazo a este ejemplo de generación en el que ejecutamos node program.js , pero el comando puede iniciar bash, Python, Ruby o cualquier otro comando o script. Si necesita pasar argumentos adicionales al comando, simplemente póngalos como argumentos de la matriz que es un parámetro para spawn() . Los datos vienen como un flujo en el data controlador de eventos:
var fs = require('fs')
var process = require('child_process')
var p = process.spawn('node', 'program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
Desde la perspectiva del node program.js comando, data es su salida estándar; es decir, la salida del terminal de node program.js .
La sintaxis de fork() es sorprendentemente similar al spawn() método con una excepción, no hay comando porque fork() asume que todos los procesos son Node.js:
var fs = require('fs')
var process = require('child_process')
var p = process.fork('program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
El último punto de nuestra agenda en esta sección es exec() . Es ligeramente diferente porque no usa un patrón de eventos, sino una sola devolución de llamada. En él, tiene parámetros de error, salida estándar y error estándar:
var fs = require('fs')
var process = require('child_process')
var p = process.exec('node program.js', function (error, stdout, stderr) {
if (error) console.log(error.code)
})
La diferencia entre error y stderr es que el primero viene de exec() (por ejemplo, permiso denegado a program.js ), mientras que el último de la salida de error del comando que está ejecutando (por ejemplo, la conexión de la base de datos falló dentro de program.js ).
Manejo de errores asíncronos
Hablando de errores, en Node.js y en casi todos los lenguajes de programación tenemos try/catch que usamos para manejar errores. Para errores síncronos, try/catch funciona bien.
try {
throw new Error('Fail!')
} catch (e) {
console.log('Custom Error: ' + e.message)
}
Los módulos y funciones arrojan errores que detectamos más tarde. Esto funciona en Java y sincrónico Nodo. Sin embargo, la mejor práctica de Node.js es escribir asincrónico código para que no bloqueemos el hilo.
El bucle de eventos es el mecanismo que permite al sistema delegar y programar el código que debe ejecutarse en el futuro cuando finalicen las costosas tareas de entrada/salida. El problema surge con los errores asincrónicos porque el sistema pierde el contexto del error.
Por ejemplo, setTimeout() funciona de forma asíncrona al programar la devolución de llamada en el futuro. Es similar a una función asíncrona que realiza una solicitud HTTP, lee de una base de datos o escribe en un archivo:
try {
setTimeout(function () {
throw new Error('Fail!')
}, Math.round(Math.random()*100))
} catch (e) {
console.log('Custom Error: ' + e.message)
}
No hay try/catch cuando se ejecuta la devolución de llamada y la aplicación falla. Eso sí, si pones otro try/catch en la devolución de llamada, detectará el error, pero esa no es una buena solución. Esos molestos errores asíncronos son más difíciles de manejar y depurar. Try/catch no es lo suficientemente bueno para el código asíncrono.
Entonces, los errores asíncronos bloquean nuestras aplicaciones. ¿Cómo lidiamos con ellos? ? Ya has visto que hay un error argumento en la mayoría de las devoluciones de llamada. Los desarrolladores deben verificarlo y mejorarlo (pasar por alto la cadena de devolución de llamada o enviar un mensaje de error al usuario) en cada devolución de llamada:
if (error) return callback(error)
// or
if (error) return console.error(error)
Otras mejores prácticas para manejar errores asíncronos son las siguientes:
- Escuchar todos los eventos "en caso de error"
- Escucha
uncaughtException - Utilice
domain(soft obsoleto) o AsyncWrap - Registrar, registrar, registrar y rastrear
- Notificar (opcional)
- Salir y reiniciar el proceso
activado('error')
Escucha todo on('error') eventos que son emitidos por la mayoría de los objetos centrales de Node.js y especialmente http . Además, cualquier cosa que herede o cree una instancia de Express.js, LoopBack, Sails, Hapi, etc. emitirá error , porque estos marcos amplían http .
js
server.on('error', function (err) {
console.error(err)
console.error(err)
process.exit(1)
})
excepción no detectada
Escucha siempre uncaughtException en el process ¡objeto! uncaughtException es un mecanismo muy crudo para el manejo de excepciones. Una excepción no controlada significa que su aplicación, y por extensión el mismo Node.js, se encuentra en un estado indefinido. Reanudar a ciegas significa que cualquier cosa podría pasar.
process.on('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
})
o
process.addListener('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
Dominio
El dominio no tiene nada que ver con los dominios web que ves en el navegador. domain es un módulo central de Node.js para manejar errores asíncronos guardando el contexto en el que se implementa el código asíncrono. Un uso básico de domain es instanciarlo y poner su código fallido dentro del run() devolución de llamada:
var domain = require('domain').create()
domain.on('error', function(error){
console.log(error)
})
domain.run(function(){
throw new Error('Failed!')
})
domain está ligeramente obsoleto en 4.0, lo que significa que el equipo central de Node probablemente separará domain desde la plataforma, pero no hay alternativas en el núcleo a partir de ahora. Además, porque domain tiene un fuerte soporte y uso, vivirá como un módulo npm separado para que pueda cambiar fácilmente del núcleo al módulo npm, lo que significa domain está aquí para quedarse.
Hagamos que el error sea asíncrono usando el mismo setTimeout() :
// domain-async.js:
var d = require('domain').create()
d.on('error', function(e) {
console.log('Custom Error: ' + e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, Math.round(Math.random()*100))
});
¡El código no fallará! Veremos un bonito mensaje de error, "Error personalizado" del error del dominio. controlador de eventos, no el seguimiento típico de la pila de nodos.
Complementos de C++
La razón por la que Node se hizo popular con el hardware, IoT y la robótica es su capacidad para funcionar bien con código C/C++ de bajo nivel. Entonces, ¿cómo escribimos el enlace C/C++ para su IoT, hardware, dron, dispositivos inteligentes, etc.?
Esta es la última característica central de este ensayo. ¡La mayoría de los principiantes de Node ni siquiera creen que pueden escribir sus propios complementos de C++! De hecho, es tan fácil que lo haremos desde cero ahora mismo.
En primer lugar, cree el hello.cc archivo que tiene algunas importaciones repetitivas al principio. Luego, definimos un método que devuelve una cadena y exporta ese método.
#include <node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::HandleScope;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); // String
}
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method); // Exporting
}
NODE_MODULE(addon, init)
}
Incluso si no es un experto en C, es fácil detectar lo que está sucediendo aquí porque la sintaxis no es tan ajena a JavaScript. La cadena es capital one :
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one"));`
Y el nombre exportado es hello :
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method);
}
Una vez hello.cc está listo, tenemos que hacer algunas cosas más. Uno de ellos es crear binding.gyp que tiene el nombre del archivo de código fuente y el nombre del complemento:
{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}
Guarda el binding.gyp en la misma carpeta con hello.cc e instale node-gyp :
$ npm install -g node-gyp
Una vez que obtuviste node-gyp , ejecute estos comandos de configuración y construcción en la misma carpeta en la que tiene hello.cc y binding.gyp :
$ node-gyp configure
$ node-gyp build
Los comandos crearán el build carpeta. Compruebe si hay compilado .node archivos en build/Release/ .
Por último, escriba el script create Node.js hello.js e incluye tu complemento de C++:
var addon = require('./build/Release/addon')
console.log(addon.hello()) // 'capital one'
Para ejecutar el script y ver nuestra cadena capital one , simplemente use:
$ node hello.js
Hay más ejemplos de complementos de C++ en https://github.com/nodejs/node-addon-examples.
Resumen
El código para jugar está en GitHub. Si te ha gustado esta publicación, deja un comentario a continuación. Si está interesado en los patrones de Node.js como las convenciones de observador, devolución de llamada y nodo, eche un vistazo a mi ensayo Patrones de nodo:de las devoluciones de llamada a observador.
Sé que ha sido una lectura larga, así que aquí hay un resumen de 30 segundos:
- Bucle de eventos:mecanismo detrás de la E/S sin bloqueo de Node
- Global y proceso:objetos globales e información del sistema
- Emisores de eventos:patrón de observador de Node.js
- Flujos:patrón de datos grandes
- Búferes:tipo de datos binarios
- Clústeres:Escalamiento vertical
- Dominio:Manejo asincrónico de errores
- Complementos de C++:complementos de bajo nivel
La mayor parte de Node es JavaScript, excepto por algunas características principales que se ocupan principalmente del acceso al sistema, globales, procesos externos y código de bajo nivel. Si comprende estos conceptos (siéntase libre de guardar este artículo y volver a leerlo unas cuantas veces más), estará en un camino rápido y corto para dominar Node.js.