Wir haben die letzten Monate damit verbracht, die neue Version unseres Warenkorbs zu erstellen.
Als wir anfingen, daran zu arbeiten, wussten wir, dass dies auch Änderungen in anderen Bereichen unseres Produkts bedeuten würde.
Dokumentation war eine davon.
Es bedeutete ein paar spezifische und dringend benötigte Upgrades:
-
Verbesserte Navigation zwischen Dokumentversionen
-
Arboreszenz von Inhalten überdenken
-
Automatisierung der Dokumentationserstellung so weit wie möglich
Wir wollten auch dem treu bleiben, was wir predigen; mit dem JAMstack! Das bedeutete, die richtigen JavaScript-Tools auszuwählen, um unsere Dokumentation zu generieren.
Wir haben uns schließlich für Nuxt für die statische Dokumentationserstellung, Sanity.io für die Verwaltung von Inhalten und Netlify für die automatisierte Bereitstellung entschieden. Warum, erkläre ich später.
Letztendlich war es eine großartige Gelegenheit, die UX unserer Dokumentation sowohl für Benutzer als auch für unser Entwicklungsteam erheblich zu verbessern.
In diesem Beitrag möchte ich Ihnen zeigen, wie wir es gemacht haben und wie Sie es nachmachen können.
Unsere Dokumentationserstellung (ein wenig Kontext)

Unser altes Dokument wurde mit benutzerdefiniertem Node.js erstellt und musste bei jedem Laden einer neuen Seite serverseitig gerendert werden. Wir haben oft vergessen, neue Korrekturen und einfache Funktionen zu dokumentieren. Es gab auch die unglücklichen Fehler und Tippfehler von Zeit zu Zeit. Kurz gesagt, die Dokumentation kann oft zum Ärgernis werden. Ich bin sicher, einige von Ihnen können sich damit identifizieren.
Für unsere neue Dokumentation haben wir uns also ein paar Ziele gesetzt. Es musste:
-
Als vollständig statische Site bereitgestellt werden
-
Auf einem schnellen CDN gehostet werden
-
Verwenden Sie Vue.js im Frontend (da es das Standard-Framework unseres Teams ist)
-
Erleichtern Sie das Bearbeiten von Inhalten für das gesamte Team – nicht nur für Entwickler!
-
Stellen Sie sicher, dass alle Methoden unserer JavaScript-API und die überschreibbaren Komponenten des Designs ordnungsgemäß dokumentiert werden
Diese Kombination von Kriterien führte zu einer offensichtlichen Wahl des Stacks:ein Vue-betriebener statischer Website-Generator, der an ein Headless-CMS angeschlossen ist.
Als Automatisierungsfans wollten wir die Dokumentation der Komponenten unseres Themes und der Javascript-API nicht unabhängig voneinander verwalten. Die Dokumentationsdaten müssten zur Erstellungszeit aus dem Code und den JSDoc-Kommentaren generiert werden.
Dies würde eine Menge zusätzlicher Arbeit erfordern, aber auf lange Sicht sollten Sie sicherstellen, dass die Dokumentation immer aktuell und validiert ist, während wir gleichzeitig die Pull-Requests der Funktionen überprüfen.
Dies fügte auch die Einschränkung hinzu, ein Headless-CMS mit einer leistungsstarken API zum Aktualisieren von Inhalten zu wählen.
Warum Sanity als Headless CMS?

Es gibt viele, viele Headless-CMS. Ich schlage vor, gründlich zu recherchieren und die Vor- und Nachteile abzuwägen, bevor Sie sich für eines entscheiden. In unserem Fall gibt es einige Kriterien, die für Sanity.io ausschlaggebend waren:
-
Hervorragende, sofort einsatzbereite Bearbeitungserfahrung
-
Vollständig gehostet – keine Notwendigkeit, dies in unserer Infrastruktur zu verwalten
-
Open Source und anpassbar
-
Hervorragende API zum Abfragen und Schreiben
-
Webhooks, mit denen wir das Dokument nach Inhaltsänderungen neu erstellen können
Der Start eines Sanity-Projekts ist unkompliziert. Führen Sie in einem neu erstellten Repo sanity init aus .
Definieren Sie dann einige Dokumenttypen und erstellen Sie, wenn Ihnen danach ist, einige benutzerdefinierte Komponenten, um die Bearbeitung an Ihre speziellen Bedürfnisse anzupassen. Selbst wenn Sie sich auf eine Anpassungstour begeben, hindert Sie dies nicht daran, Ihr CMS auf Sanity bereitzustellen – dort glänzt es wirklich, da eine hohe Anpassbarkeit bei gehosteten Lösungen eine ziemlich seltene Eigenschaft ist.
Die API von Sanity war auch ein Hauch frischer Luft.
GROQ, ihre Abfragesprache, ist eine willkommene Ergänzung des Ökosystems. Denken Sie an GraphQL, ohne dass Sie immer explizit alle gewünschten Felder in einer Abfrage angeben müssen (oder polymorphe Daten abfragen können, ohne sich wie die Arbeiten des Herkules zu fühlen).
Darüber hinaus können Änderungen in einer Transaktion festgelegt werden, was es uns ermöglicht, Aktualisierungen mehrerer Dokumente aus unserem Design- und SDK-Build-Prozess zu stapeln. Kombinieren Sie dies mit Webhooks und es stellt sicher, dass wir die Dokumentationsbereitstellung nur einmal für viele Änderungen aus unseren Design- und SDK-Repositories auslösen.
Warum Nuxt als Static-Site-Generator?

Gerade als Sie dachten, es gäbe eine Menge Headless-CMS zur Auswahl, stolpern Sie über Dutzende von bestehenden SSGs.
Die Hauptanforderungen für unseren statischen Seitengenerator waren:
-
Stellt nur statische Dateien bereit
-
Verwendet Vue.js
-
Ruft Daten von einer externen API ab
Die Verwendung von Vue.js mag hier willkürlich erscheinen, und Sie fragen sich zu Recht:„Warum nicht reagieren oder etwas anderes?“ Ehrlich gesagt war es anfangs etwas willkürlich, da es auf die persönlichen Vorlieben des Teams hinausläuft, aber da wir immer mehr Projekte erstellen, legen wir auch Wert auf Konsistenz bei allen.
Wir verwenden Vue.js seit langem im Dashboard und haben uns für unser Standard-v3.0-Design entschieden. Letztendlich wird uns diese Konsistenz nicht nur ein schnelleres Onboarding von Teammitgliedern ermöglichen, sondern auch die Wiederverwendung von Code. Angenommen, wir möchten eine Live-Vorschau der Designanpassung erstellen. Das Teilen des gleichen Stacks zwischen den Dokumenten und dem Design macht das einfacher.
Davon abgesehen blieben uns drei SSG-Konkurrenten:VuePress, Nuxt &Gridsome.
→ VuePress . Die integrierte Unterstützung für Inline-Vue-Komponenten im Inhalt war wirklich verlockend, aber ohne die Option, eine externe Datenquelle anstelle lokaler Markdown-Dateien anzuzapfen, war dies ein No-Go.
→ Nuxt.js. Dies ist ein Kraftpferd der SPA-Entwicklung mit Vue. Es bietet eine großartige Struktur und genau die richtigen Erweiterungspunkte, um wirklich flexibel zu sein. Die nuxt generate Der Befehl ermöglicht die Bereitstellung einer vollständig statischen und vorgerenderten Version der Website. Das Erstellen einer inhaltsgesteuerten Website anstelle einer dynamischen Webanwendung erfordert jedoch zusätzliche Arbeit.
→ Gridsome . Direkt von Gatsby inspiriert, bietet es erstklassige Unterstützung für externe Datenquellen und wurde entwickelt, um statische Websites aus diesen Daten zu erstellen. Nachdem ich bereits damit experimentiert hatte und weil es alle Kästchen angekreuzt hatte, schien Gridsome zuerst wie der Auserwählte.
Wir sind jedoch schnell auf einige Schmerzpunkte gestoßen:
-
Die automatische Generierung des GraphQL-Schemas weist einige Probleme auf und erfordert häufig die manuelle Angabe des Feldtyps.
-
Wir konnten unsere Daten nicht so strukturieren, wie wir wollten. Wir mussten
functionspeichern ,classundenum, die alle auf polymorphe Weise mit Dokumentationsseiten verknüpft werden mussten. -
Seien wir ehrlich, der Umgang mit dem GraphQL-Schema verlangsamt einfach die Iterationszyklen.
Insgesamt fehlte Gridsome ein wenig die Reife, wenn es um ein komplexes Schema geht. Was GraphQL betrifft, so zeichnet es sich in Szenarien aus, in denen Sie mehrere Datennutzer haben, die an verschiedenen Abfragen interessiert sind. In unserem Fall wurden dadurch nur unnötige Schritte hinzugefügt.
Am Ende haben wir uns entschieden, Nuxt zu verwenden und die fehlenden Teile manuell zu entwickeln.
Alles, was an dieser Stelle fehlt, ist etwas, um unsere Dokumentation bereitzustellen. Für uns gab es keine Diskussion. Netlify ist hier ein Kinderspiel, also wurde es das letzte fehlende Stück in unserem Stack.
Unsere neue Dokumentationsgeneration im Javascript-Stil
Bevor wir uns in technische Kleinigkeiten stürzen, werfen wir einen Blick auf diesen Stack, der alle miteinander verdrahtet ist. JAMstack-Projekte können sich aufgrund der Anzahl der verwendeten Tools manchmal überwältigend anfühlen, aber Sie können sie nach ihrem spezifischen Wert auswählen.
Obwohl einige Einzelteile relativ komplex sind, war das Zusammensetzen recht einfach.

Unsere Dokumentation besteht aus traditionellen Inhaltsseiten, die von unserem Entwickler- oder Marketingteam geschrieben wurden, und technischen Inhalten, die aus zwei Repositories extrahiert wurden:
-
Das Dokument des Javascript-SDK (ähnlich unserer handgefertigten V2-JavaScript-API)
-
Das Dokument der Vue.js-Designkomponenten (neu in v3.0 zum Überschreiben von Komponenten)
Inhaltsseiten werden direkt in Sanity CMS bearbeitet. Der technische Inhalt wird automatisch mit der Compiler-API von Typescript generiert und in einem Skript auf unserem CI an die API von Sanity gepusht, wenn jedes Repo aktualisiert wird. Dieses Skript verwendet die Transaktionsfunktion von Sanity, um alle Änderungen auf einmal zu aktualisieren.
Änderungen von Sanity generieren einen Webhook, den wir verwenden, um einen Build auf Netlify auszulösen. Die Handhabung von Webhooks in einem JAMstack-Setup erfordert häufig die Verwendung einer Art Lambda-Funktion als Logikschicht zwischen dem Webhook der Quelle und der API des Ziels.
Hier können wir jedoch die clevere Voraussicht von Netlify nutzen. Ihr eingehender Webhook-Endpunkt ist eine einfache private URL, die jede POST-Anforderung akzeptiert, um einen Build auszulösen – was bedeutet, dass der Webhook von Sanity direkt dafür konfiguriert werden kann!
Sobald der Build gestartet ist, wird nuxt generate ausgeführt . Unser benutzerdefinierter Code ruft Daten von Sanity und dem dist ab Ordner auf einem blitzschnellen CDN bereitgestellt werden.
Kurz gesagt, Sanity dient als Speicher für alles, was in unseren Dokumenten benötigt wird. Die Dokumentation selbst ist immer auf dem neuesten Stand mit allem, was in der Produktion veröffentlicht wird. Dokumentation aus Quellen kann als Teil eines regelmäßigen Codeüberprüfungsprozesses validiert werden.
Dokumentation aus Quellen generieren
Da alle unsere v3.0-Projekte in Typescript vorliegen, können wir die Compiler-API nutzen, um Dokumentation aus dem Quellcode zu extrahieren. Dies geschieht in drei Phasen:
-
Der Compiler generiert automatisch Typdefinitionen (eine
.d.tsDatei) des Projekts mit Ausnahme aller als intern gekennzeichneten Typen (mit@internal). Tags in JSDoc-Kommentaren). Dies wird einfach durch Setzen vondeclarationerreicht undstripInternalbistruein unseremtsconfig.json -
Unser benutzerdefiniertes Skript wird ausgeführt; es liest den
.d.tsDatei, analysieren sie mit der Compiler-API und übergeben das Ergebnis an eine Bibliothek namens readts, die die Ausgabe des Compilers in eine besser verwaltbare Datenstruktur umwandelt. -
Schließlich aktualisiert unser Skript die Datenbank von Sanity mit ihrem npm-Modul.
Nehmen wir diese Funktion als Beispiel:
/**
* Initialize the SDK for use in a Web browser
* @param apiKey Snipcart Public API Key
* @param doc Custom document node instead of `window.document`
* @param options Initialization options
*/
export async function initializeBrowserContext(
apiKey?: string,
doc?: HTMLDocument,
options?: SnipcartBrowserContextOptions) : Promise<SDK> {
// some internal code
}Es wird fast so wie es ist in die Typdeklaration unseres SDK exportiert, abzüglich des Hauptteils der Methode. Der folgende Code ermöglicht es uns, ihn strukturiert zu konvertieren:
const parser = new readts.Parser();
parser.program = ts.createProgram(["snipcart-sdk.d.ts"]);
parser.checker = parser.program.getTypeChecker();
parser.moduleList = [];
parser.symbolTbl = {};
// the compiler will load any required typescript libs
// but we only need to document types from our own project
const source = parser.program
.getSourceFiles()
.filter(s => s.fileName === "snipcart-sdk.d.ts")[0];
// we instruct `readts` to parse all
// `declare module 'snipcart-sdk/*' {...}` sections
for (const statement of source.statements) {
parser.parseSource(statement);
}
const result = parser.moduleList.map((module) => {
/* some more transformations */
});Nach dem Hochladen in den Datensatz von Sanity sieht die vorherige Funktionsdeklaration so aus:
{
"_id": "sdk-contexts-browser-initializeBrowserContext",
"_type": "sdk-item",
"kind": "function",
"name": "initializeBrowserContext",
"signatures": [
{
"doc": "Initialize the SDK for use in a Web browser",
"params": [
{
"doc": "Snipcart Public API Key",
"name": "apiKey",
"optional": true,
"type": {
"name": "string"
}
},
/* other params */
],
"returnType": {
"id": "sdk-core-SDK",
"name": "SDK"
},
}
]
}
Die Verwendung von Readts mag wie ein Spaziergang im Park aussehen, aber die Verwendung der Compiler-API von Typescript ist nichts für schwache Nerven. Sie müssen sich oft mit den Symbolen des Compilers (nicht zu verwechseln mit denen aus der Sprache), den AST-Knoten und ihren SyntaxKind befassen Enum-Werte.
Die Daten sind jetzt bereit, von unserem SSG verarbeitet zu werden, sehen wir uns an, wie wir Nuxt verdrahtet haben!
Nuxt vollständig statisch und inhaltsgesteuert machen
Durch seinen nuxt generate Befehl kann Nuxt.js zur Erstellungszeit eine vollständig statische Website generieren.
Im Gegensatz zu Gatsby oder Gridsome, die die Inhaltsknoten zwischenspeichern, wird das Abrufen von Daten jedoch auch im statischen Modus mit Nuxt durchgeführt. Es passiert, weil asyncData -Methode wird immer aufgerufen, und es ist Sache des Entwicklers, bei Bedarf eine eindeutige Logik bereitzustellen. Es gibt bereits einige Gespräche darüber, dies in der Nuxt-Community zu beheben. Aber wir brauchten es JETZT 🙂
Wir sind dieses Problem mit einem Nuxt-Modul angegangen, das sich beim Aufruf vom Client (der statischen Website) oder vom Server (wenn nuxt generate wird genannt). Dieses Modul wird in unserem nuxt.config.js deklariert :
modules: [
"~/modules/data-source",
],Dann registriert es einfach ein Server- und Client-Plugin:
export default async function DataSourceModule (moduleOptions) {
this.addPlugin({
src: path.join(__dirname, 'data-source.client.js'),
mode: 'client',
});
this.addPlugin({
src: path.join(__dirname, 'data-source.server.js'),
mode: 'server',
});
}Beide stellen dieselbe Methode für die Komponente jeder Seite bereit, um Daten zu laden. Der Unterschied besteht darin, dass diese Methode auf dem Server die Nuxt-API direkt aufruft, um Inhalte abzurufen:
// data-source.server.js
import { loadPageByUrl } from '~/sanity.js';
export default (ctx, inject) => {
inject('loadPageData', async () => {
return await loadPageByUrl(ctx.route.path);
});
}Auf dem Client lädt das Plugin stattdessen eine statische JSON-Datei:
// 'data-source.client.js'
import axios from 'axios';
export default (ctx, inject) => {
inject('loadPageData', async () => {
const path = '/_nuxt/data' + ctx.route.path + '.json';
return (await axios(path)).data;
});
}
Jetzt können wir in der Komponente unserer Seite loadPageData blind aufrufen und das Modul und die Plugins garantieren, dass die richtige Version verwendet wird:
<!-- page.vue -->
<template>
<Markdown :content="page && page.body || ''" />
</template>
<script>
import Markdown from '~/components/Markdown';
export default {
props: ['page'],
components: {
Markdown,
},
async asyncData() {
return await app.$loadPageData();
}
}
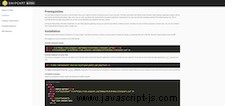
</script>Hier ist ein kleiner Vorgeschmack, wie die Funktion, über die ich zuvor gesprochen habe, in der Dokumentation aussieht:

Das Endergebnis
Abschlussgedanken
Der Einstieg in Sanity war ein Kinderspiel, und obwohl wir es noch nicht weit getrieben haben, sieht alles so aus, als wäre es so konzipiert, dass es reibungslos erweitert werden kann. Ich war wirklich beeindruckt von ihrer API, Abfragen mit GROQ und wie Plugins für das CMS erstellt werden können.
Obwohl Nuxt für unseren Anwendungsfall mehr Arbeit erforderte, bietet es dennoch eine starke Basis, um damit jedes Vue.js-Projekt zu erstellen.
Nach all dieser knusprigen Vorarbeit sind wir bereit, weitere kosmetische Verbesserungen an der Dokumentation vorzunehmen, wie z. B. eine bessere Auffindbarkeit und Organisation unserer SDK-Methoden.
Wenn Ihnen dieser Beitrag gefallen hat, nehmen Sie sich bitte einen Moment Zeit, um ihn zu teilen auf Twitter . Haben Sie Kommentare, Fragen? Klicken Sie auf den Abschnitt unten!