In diesem Artikel werde ich ein kurzes Beispiel geben, wie man ganze Datenbanken (sei es MongoDB, Elasticsearch oder RDBS wie PostgreSQL) mit modernen JavaScript-Tools verarbeiten kann. Wir werden async/await, Iteratoren und Funktionsgenerator in einem einfachen, aber leistungsstarken Muster kombinieren, das in vielen Fällen verwendet werden kann.
Siehe Arbeitsbeispiel auf Runkit.
Das Problem
Unser Fall ist es, die gesamte Datenbank (Tabelle in RDB, Sammlung in Mongo) Eintrag für Eintrag zu verarbeiten.
Der einfachste Weg wäre, alle Dokumente auszuwählen, sie in den Laufzeitspeicher zu legen und alle Operationen auszuführen. Dies ist jedoch nicht die Antwort, insbesondere wenn der Datensatz groß und unser Speicher begrenzt ist.
Klassischer Ansatz:Limit und Offset
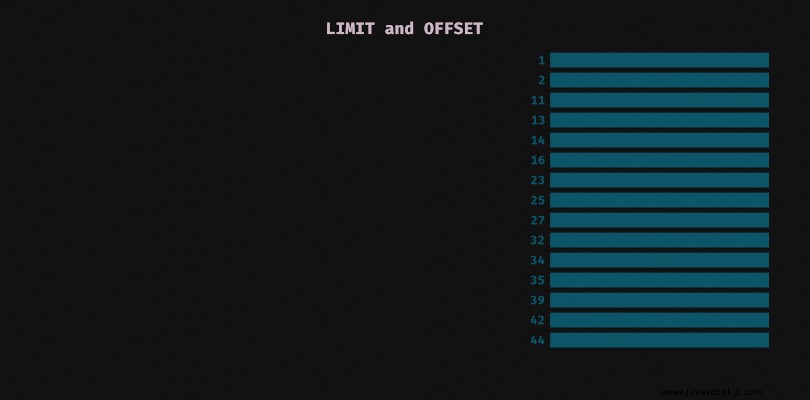
Es besteht die Möglichkeit, limit zu verwenden kombiniert mit offset im SQL:
SELECT * FROM my_table LIMIT 50 OFFSET 100;
was in Mongo so aussehen würde:
db.my_collection.find({}).skip(100).limit(50)
Beachten Sie, dass sich die Leistung dieser Technik in den meisten Datenbanken basierend auf dem Offset-Wert ändert. Je größer der Offset ist, desto langsamer wird die Abfrage. Dies liegt daran, dass die Datenbank in den meisten Fällen alle übersprungenen Einträge verarbeitet, bevor sie diejenigen zurückgibt, die uns interessieren. Aufgrund dieses Hindernisses spezifizieren einige Datenbanken den maximalen Versatzwert, sodass es möglicherweise nicht möglich ist, die gesamte Datenbank ohne zusätzliche Anpassungen an den Datenbankeinstellungen zu verarbeiten.
Statusbehaftete Cursor
Wir könnten die Stateful-Technik mit cursors nutzen . Cursor ist ein Objekt, das von der Datenbank erstellt und in ihrem Speicher gehalten wird. Es erinnert sich an den Kontext einer Abfrage, z. aktueller Stand der Paginierung. Normalerweise müssen wir einen Cursor erstellen und dann in weiteren Abfragen einen Verweis darauf verwenden.
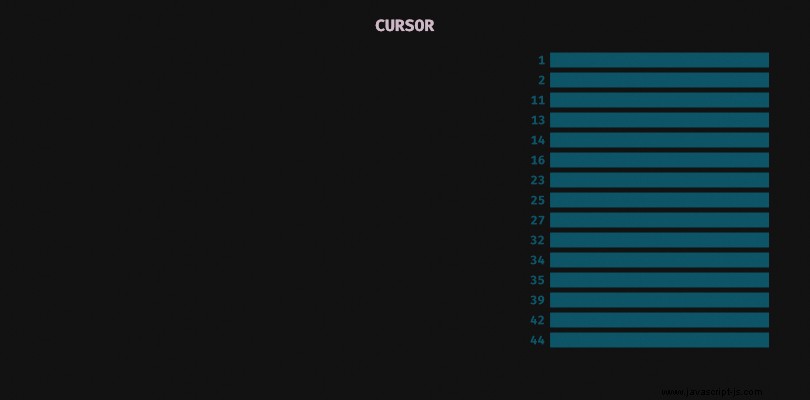
Beachten Sie, dass der Cursor in einigen Datenbanken seine Lebensdauer hat. In Elasticsearch können wir beispielsweise die Ablaufzeit für den Suchkontext in scroll angeben Parameter.
Sie können auch auf eine Begrenzung der maximalen Anzahl gleichzeitig geöffneter Cursor stoßen.
Eine Alternative:Bereichsabfrage
Die nächste Technik - Bereichsabfrage - hat einige interessante Features.
- Es ist staatenlos . Das bedeutet, dass Sie sich nicht um den Statusablauf oder die Statussynchronisierung zwischen allen Datenbankknoten in Ihrem Netzwerk kümmern müssen.
- Es hat eine konstante und kontrollierbare Speichernutzung . Das bedeutet, dass es erfolgreich auf Computern mit wenig Speicher verwendet werden kann und seine Leistung nicht von der Größe des Datensatzes oder dem Fortschritt der Paginierung abhängt.
- Es ist nicht datenbankspezifisch . Schließlich ist es nur ein Ansatz, wie man eine Abfrage so konstruiert, dass sie in den meisten Datenbanken verwendet werden kann.
Die Bereichsabfrage ist der Kombination aus Limit und Offset sehr ähnlich. Anstatt jedoch die Anzahl der zu überspringenden Dokumente anzugeben, geben wir eine Randbedingung an, die bereits verarbeitete Dokumente eliminiert.
Im Beispieldatensatz (unten dargestellt) werden die Dokumente aufsteigend nach ID sortiert. Bedingung id > 16 überspringt 6 Dokumente mit IDs:1 , 2 , 11 , 13 , 14 , 16 . Das Ergebnis ist identisch mit der Angabe des Offsets gleich 6.
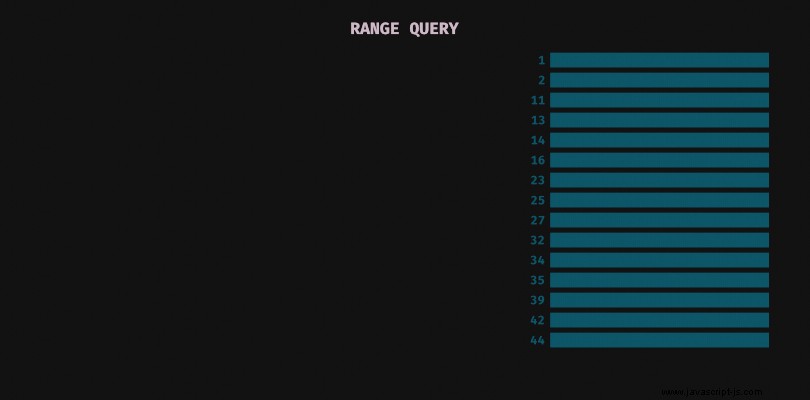
Das Iterieren über Datasets in Stapeln der Größe 6 besteht aus 3 Schritten:
- erste 6 Dokumente anfordern und ID des letzten Dokuments merken (16 ),
- Fordere die nächsten 6 Dokumente mit der Bedingungs-ID> 16 an , merken Sie sich die letzte ID (35 ),
- Fordere die nächsten 6 Dokumente mit Bedingungs-ID> 35 an . Beachten Sie, dass dieses Mal nur 3 Dokumente zurückgegeben wurden, was bedeutet, dass unser Datensatz am Ende ist.
Dinge, die Sie sich merken sollten:
- Datensatz muss sortiert sein nach Schlüssel, auf den unsere Bedingung angewendet wird,
- Um die beste Leistung zu erzielen und die Speichernutzung konstant zu halten, sollte das verwendete Feld indiziert werden ,
- auch Werte in diesem Feld müssen eindeutig sein . Wenn dies nicht der Fall ist, kann die Bereichsabfrage einige Dokumente „verlieren“.
In unserem Beispiel verwenden wir eine Bereichsabfrage.

Asynchrone Iteration in JavaScript
Wir werden async-await verwenden kombiniert mit functions generator und benutzerdefinierter iterator .
Diese Kombination heißt async iteration und seinen Vorschlag finden Sie hier. Einzelne Teile waren jedoch früher in NodeJS enthalten, die gesamte Combo kann seit Version 10 innerhalb der for-Schleife verwendet werden.
Am Ende wollen wir in der Lage sein, die for-Schleife zu verwenden, um synchron über die Datenbank zu iterieren.
In Codeschnipseln in diesem Artikel gehe ich davon aus, dass wir Database haben Objekt im Gültigkeitsbereich mit Methode select , der Promise zurückgibt Auflösung in eine Reihe von Dokumenten. Es akzeptiert als Argument ein Objekt mit zwei Eigenschaften:idGreaterThan - der den Zustand in der Datenbank bestimmt, und limit - die Anzahl der zurückgegebenen Dokumente, z. B. db.select({ idGreaterThan: 6, limit: 2}) entspricht der SQL-Abfrage SELECT * FROM exoplanets WHERE id > 6 ORDER BY id ASC LIMIT 2 . In diesem Artikel habe ich die Implementierung für Database weggelassen Klasse, aber ein einfaches Mock finden Sie in diesem RunKit-Notebook. Dieses Notizbuch enthält auch funktionierende Codebeispiele, die wir schreiben werden.
readDocuments Funktionsgenerator
MDN Web Docs bietet eine hervorragende Erklärung zu Funktionsgeneratoren und Iteratoren in Javascript. Für diesen Artikel müssen wir wissen, dass Generatoren nach dem Aufruf einen Iterator zurückgeben. Und iterator ist ein Objekt, das in einer for..of-Schleife verwendet werden kann.
Schreiben wir unseren Generator readDocuments .
/**
* Iterate over database
* @generator
* @function readDocuments
* @param {number} limit maximum number of documents
* @yields {array} list of planets
*/
async function* readDocuments(limit) {
const db = new Database();
let lastId = 0; // initialize with min value
let done = false; // indicates end of iteration
while(!done) {
// select batch of documents and wait for database response
// TODO: error handling
const result = await db.select({
idGreaterThan: lastId,
limit: limit
});
// get id of last document
lastId = result[result.length - 1].id;
// end iteration if there are less documents than limit
if(result.length < limit) {
done = true;
}
// yield result
yield result
}
};
Beachten Sie zwei wichtige Dinge im obigen Code:readDocuments wird beides mit async deklariert Schlüsselwort und function* Ausdruck. Diese Funktion ist eine Mischung aus asynchroner Funktion und Funktionsgenerator und hat beides. Analysieren wir es aus zwei Perspektiven.
Als asynchrone Funktion ermöglicht es uns, auf eine asynchrone Datenbankoperation zu warten. Das bedeutet, dass sich die While-Schleife synchron verhält. Jede Auswahl aus der Datenbank wird erst ausgeführt, nachdem die vorherige abgeschlossen wurde.
Anstatt result zurückzugeben wir yield es. Das ist ein Teil davon, der Funktionsgenerator zu sein. Wie ich oben erwähnt habe, geben Generatoren einen Iterator zurück, der in for-Schleifen verwendet werden kann. Jedes Mal, wenn der Generator etwas liefert, bricht das Programm von der Funktion ab und geht zum Hauptteil der Schleife.
Dies bringt uns zur bekannten for..of-Schleife, jedoch in einer asynchronen Variante.
async function run() {
// We need to place our loop inside another async function
// so we can use await keyword
for await (let documents of readDocuments(4)) {
// This for loop behaves synchronously.
// Next iteration will begin after execution of code inside this loop
await doSomethingWithDocuments(documents);
}
}
run();
Das ist es! Im Runkit-Beispiel protokolliere ich einfach Planeten, um jede Iteration zu trösten. Sie sollten eine Ausgabe sehen, die der folgenden ähnelt.
DATABASE: SELECT * FROM exoplanets ORDER BY id ASC LIMIT 4
APP: Got 4 items from database: Proxima Centauri b, Gliese 667 Cc, Kepler-442b, Kepler-452b. Done: false
DATABASE: SELECT * FROM exoplanets WHERE id > 7 ORDER BY id ASC LIMIT 4
APP: Got 4 items from database: Wolf 1061c, Kepler-1229b, Kapteyn b, Kepler-62f. Done: false
DATABASE: SELECT * FROM exoplanets WHERE id > 14 ORDER BY id ASC LIMIT 4
APP: Got 4 items from database: Kepler-186f, Luyten b, TRAPPIST-1d, TRAPPIST-1e. Done: false
DATABASE: SELECT * FROM exoplanets WHERE id > 18 ORDER BY id ASC LIMIT 4
APP: Got 4 items from database: TRAPPIST-1f, TRAPPIST-1g, LHS 1140 b, Kepler-1638b. Done: false
DATABASE: SELECT * FROM exoplanets WHERE id > 24 ORDER BY id ASC LIMIT 4
APP: Got 1 items from database: Teegarden c*. Done: true
Ich hoffe, Ihnen hat dieser Artikel gefallen. Im nächsten Artikel dieser Serie werde ich zeigen, wie Sie dieses Tool verwenden können, um große Dateien zu lesen, wenn der Speicher begrenzt ist. Bleiben Sie dran!
Acks 🦄
- Titelfoto von Florencia Viadana auf Unsplash
- Exoplaneten in Beispielen aus Wikipedia