Strojové učení pro řemeslníky:Klasifikace krajkářských technik
Použití pokročilých inferenčních technik při návštěvě muzejní sbírky nemusí být zřejmé. Proč by bylo strojové učení užitečné pro analýzu starožitných textilií? Za prvé, správa sbírek může velmi těžit z „inteligentního“ označování sbírek, které jsou v procesu archivace. Digitalizace muzejních sbírek, což je hlavní oblast úsilí v posledním desetiletí, se soustředila na zpřístupnění sbírek online, často kus po kusu.
Tato práce je samozřejmě zásadní pro vytváření dat, která lze využít strojovým učením ke zlepšení modelů. Práce je soběstačná:čím více položek je uvedeno online a digitalizováno pro veřejnou spotřebu, tím lepší jsou modely, které lze vyrábět ze stále rostoucí skupiny položek. A čím lepší modely, tím snazší bude katalogizace položek rychleji. Archivní práce by nakonec mohla být podstatně méně manuální, pokud lze k jejich kategorizaci a označování použít pokročilé techniky strojového učení.
V tomto článku se podíváme na některé nástroje, které pomáhají klasifikovat položky podle jejich obrázku. V tomto procesu nabízíme plán pro vytvoření klasifikačního systému na míru pro kategorizaci položek podle jejich obrázku. Můžeme otestovat konkrétní případ použití pro určení kategorií krajek podle jejich fotografie. Vytvořením webové aplikace s vlastním modelem strojového učení, který lze používat offline, můžeme vytvořit užitečný nástroj pro archiváře.
Módní dekorace
Proces kroucení nití nebo provázků k výrobě nových látek v dekorativní prolamovaném dílu byl ručním řemeslem již od starých Egypťanů. Krajkařství se vyvinulo a stalo se vysoce sofistikovanou uměleckou formou. Od renesance až po edwardiánskou éru byla ručně vyráběná krajka posledním slovem v luxusu. Krajka, rozšířená po celé Evropě po stovky let, se vyvíjela spolu s měnící se módou.
Sumptuary zákony se často pokoušely regulovat, kdo může nosit drahý materiál. Přesto by 'Merveilleuse', 'dandy' nebo 'Makarony' mohly zničit jmění tím, že by na vrcholu módy utrácely drahé dovážené krajky. Chytrý ministr financí Ludvíka XIV., Colbert, si uvědomil, kolik peněz bylo vynaloženo na tuto neodolatelnou parádu. Pomohl rozjet velmoc francouzského krajkářství tím, že dovezl krajkářky z Benátek, aby tamní krajkářky učily nové techniky. Podle jeho plánu by se tak peníze utratily za domácí krajku, čímž by se snížila touha po importovaném skvostu. Od 17. do 19. století evropské země mezi sebou soupeřily o vytvoření nejmódnějších a nejkrásnějších vzorů a stylů.

Zábavná báseň, kterou napsal někdo z okruhu Mme. de Sevigny, popisuje zoufalství antropomorfizovaných cizích krajek, když jim bylo řečeno, že se musí vrátit do svých zemí – ze strachu, aby je roztrhali rozzlobení krajkáři – kvůli Colbertovu ediktu z roku 1660:

V současnosti zůstává mnoho historických krajek zamčeno v soukromých sbírkách nebo složeno v textilních odděleních muzeí. Správa a vylepšování takové kolekce vyžaduje sofistikovanou úroveň znalectví k odhalení rozdílů například mezi základními kategoriemi jehlové krajky a paličkované krajky. Například rozlišování mezi jemnými variacemi různých regionálních sítí je zásadní pro pochopení původu. Šestihranné kroucené pruhy krajky Alençon se liší od diamantové síťoviny nebo réseau Valencienne.
Vytvoření řešení strojového učení, které bude rozpoznávat kategorie krajek, představuje zajímavou výzvu, která umožní potenciálnímu sběrateli objevit jak příslib, tak výzvy, které jsou spojeny s vytvořením spolehlivého modelu rozpoznávání obrazu. Než začnete se sběrem dat, je poučné porozumět základním konceptům rozpoznávání obrazu pomocí strojového učení.
Začínáme s rozpoznáváním obrázků
Váš model je jen tak dobrý, jak dobrá je otázka, kterou na něj položíte. To znamená, že pokud máte pouze několik obrázků, na kterých můžete trénovat, nebo velké mezery ve vaší datové sadě, model nebude schopen porozumět tomu, co má za úkol klasifikovat. Řekněme, že máte například datovou sadu starožitných tlačítek a chcete určit, které z nich jsou tlačítka ve stylu „kaliko“. Pokud nemáte dobré příklady k ukázce modelu, nebude schopen odpovědět na vaši otázku „Je toto tlačítko kaliko?“
Z tohoto důvodu si při prvních iteracích tvorby modelu položte jednoduchou otázku, která odráží datovou sadu, kterou jste schopni poskytnout. V mém osobním vlastnictví jsou vzorky starožitné krajky. Mají tendenci pocházet z 19. století, takže mají zvláštní styl a jsou v různém stavu. Navrhuji použít omezený model, který jsem schopen vytvořit, abych mohl navštívit větší sbírku lepších příkladů a pomoci klasifikovat několik typů krajek. Jelikož mám vzorky krajek Honiton, Duchesse, Alençon, Point de Paris, Venetian a Coraline, je to šest tříd, na kterých budu modelku trénovat. Později, když navštívím muzeum, mohu shromáždit další data prostřednictvím videa, abych vylepšil a rozšířil model tím, že shromáždím více obrázků a přeškolím jej. Mezitím je užitečné mít webovou aplikaci, kterou lze spustit na vašem telefonu a spustit model – v případě potřeby offline – a zkontrolovat jeho přesnost s novými obrázky krajky.
Máme tedy připravený plán:vytrénovat model pro použití ve webové aplikaci. To znamená, že je třeba sestavit dvě aktiva:model a jeho webovou aplikaci.
Základy rozpoznávání obrázků
Než se pustíte do projektu strojového učení, je užitečné porozumět určité slovní zásobě. Podobně je poučné dozvědět se o některých architektonických volbách, které je třeba učinit. Každý z nich má kompromisy.
TensorFlow – TensorFlow, vyvinutý společností Google, je celá platforma pro strojové učení, která se skládá z ekosystému nástrojů, který pomáhá výzkumníkům, datovým vědcům a vývojářům vyvíjet a zavádět modely strojového učení. TensorFlow má verzi svých rozhraní API, kterou mohou přímo používat vývojáři JavaScriptu s názvem TensorFlow.js. Modely TensorFlow lze také exportovat v „odlehčeném“ formátu pro použití v mobilních aplikacích a na okrajových zařízeních, jako je Raspberry Pis. „Název TensorFlow pochází z operací, které takové neuronové sítě provádějí na vícerozměrných datových polích, která se označují jako tenzory“. TensorFlow je vynikající volbou pro webové vývojáře, kteří se chtějí dozvědět o strojovém učení vytvářením aplikací.
model - Model je soubor, který se vytvoří, když algoritmy strojového učení iterují data a hledají vzory. Dokumentace TensorFlow jej definuje jako „funkci s naučitelnými parametry, která mapuje vstup na výstup“. Dobrý model byl trénován na dobrých datech a poskytuje přesné výstupy pro vstupy, které ještě „neviděl“.
závaží - 'váha' rozhoduje, jak velký vliv bude mít vstup na výstup.
školení - daný datový soubor, rozdělený na 'trénovací' a 'testovací' sady, tréninkový proces zahrnuje pokus předpovědět výstup, daný vstupem. Zpočátku tréninkový proces produkuje mnoho chyb. Učením se z těchto chyb se tréninkový proces zlepšuje a výstupy se zpřesňují. Iterativní proces poskytování více a lepších dat procesu strojového učení a přetrénování modelu obecně vytváří stále přesnější model.
předtrénovaný vs. vlastní - zatímco vytvoření zcela nového modelu založeného na zcela novém souboru dat je možné, obecně velké množství dat potřebných k vytvoření přiměřeně přesného modelu vyžaduje více výpočtů a více dat, než je obecně dostupné pro jednotlivého praktika. Z tohoto důvodu lze mnoho modelů strojového učení generovat z předem trénovaných modelů. Tyto nové modely staví na „znalostech“ získaných předchozím školením. Toto nové školení lze provést pomocí konceptu transfer learningu. Přenosové učení umožňuje, aby řešení získaná trénováním jedné datové sady byla aplikována na druhou. Pro rozpoznávání obrázků je to obzvláště užitečná strategie, protože nový soubor dat lze použít k trénování modelu, který již byl natrénován na podobných datech.
Nástroje obchodu
K sestavení modelu rozpoznávání obrázků máte k dispozici mnoho nástrojů. Celý model lze sestavit ručně pomocí notebooků Jupyter a skriptů Python, s Cloud compute pro velké modely, které vyžadují rozsáhlé školení. Alternativně můžete pro malé důkazy konceptu a pro testování vod pomocí strojového učení vyzkoušet několik vynikajících nástrojů s nízkým kódem, které jsou na trhu nové. Jedním z takových bezplatných nástrojů je Lobe.
Lobe je bezplatná aplikace, kterou si stáhnete do svého místního počítače a nahrajete do něj obrázky pro odvození. Veškerá školení a ukládání obrázků je řešeno lokálně, jde tedy o velmi cenově výhodné řešení. Když se však váš model zvětší, možná budete chtít spolupracovat s poskytovatelem cloudu (například Google, Microsoft nebo AWS) na správě dat a modelů. Správa modelu strojového učení je iterativní proces, při kterém shromažďujete obrázky a postupně na nich trénujete model. Lobe dělá tento proces bezproblémovým automatickým přeškolením pokaždé, když je přidán a označen nový obrázek, nebo pokaždé, když je obrázek testován. Pokud model uhodne obrázek nesprávně, bude uživatel vyzván k přeznačení a model se přeškolí. Pro malé datové sady, kde chcete mít plnou kontrolu nad tím, jak se s modelem pracuje lokálně, je Lobe skvělým nástrojem.
Jako vždy je hledání obrázků, na kterých lze modelku trénovat, výzvou. U zakázkových, muzejních datových sad neobvyklých věcí je výzva dvojnásobná. Existuje několik strategií pro shromažďování obrázků pro školení:
1. Použijte rozšíření prohlížeče k seškrábání obrázků z webu. Rozšíření "Stáhnout všechny obrázky" je velmi užitečné; ujistěte se, že obrázky lze použít pro váš účel, pokud existuje licence.
2. Pořiďte video a rozdělte jej na samostatné snímky na snímek. Použijte FFMPEG k rozdělení videa stažením bezplatné knihovny ffmpeg a konverzí vašich videí.
- Pokud máte video .mov (například z iPhonu), převeďte soubory na .mp4 pomocí nástrojů příkazového řádku počítače, jako je Terminál. Zadejte
cdpřejděte na místo, kde je váš soubor nalezen, a zadejte:ffmpeg -i movie.mov -vcodec copy -acodec copy out.mp4převést soubor .mov na .mp4. - Dále vezměte soubor .mp4 a převeďte každý snímek na očíslovaný soubor obrázku zadáním
ffmpeg -i out.mp4 img_%04d.jpg. Z filmového souboru bude vygenerována řada očíslovaných obrázků.
3. Použijte nástroj, jako je Lobe, pro převod videa při práci se svou sbírkou. Lobe obsahuje video nástroj, který umožňuje uživateli pořizovat krátká videa objektu; video se poté automaticky převede na obrázky. Ujistěte se, že máte dobré osvětlení a dobrou webovou kameru pro získání kvalitních snímků. Je to dobrá volba pro rychlé vytvoření velkého množství obrázků na základě vaší sbírky.
Trénujte a otestujte svůj model
Jakmile shromáždíte položky, na kterých chcete trénovat svůj model, použijte Lobe ke shromažďování jejich obrázků buď prostřednictvím nahrání obrázku nebo pomocí nástroje pro video. Klasifikujte je tak, že vyberete skupiny obrázků a označíte je. Toto jsou vaše třídy. Model se bude postupně trénovat, jak budete přidávat obrázky. Až budete připraveni to otestovat, najděte online nějaké obrázky třídy, kterou chcete testovat, a postupně je vložte do „hrací“ oblasti rozhraní Lobe. Vylepšete model uvedením, zda je Lobeův odhad ohledně třídy obrázku správný nebo nesprávný.
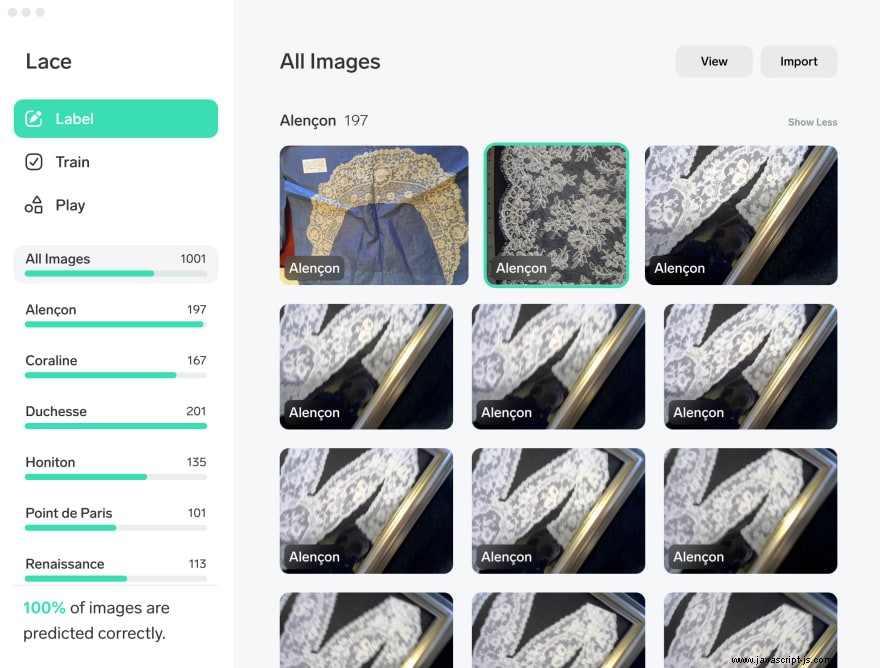
Jakmile budete s její přesností spokojeni, exportujte ji jako model TensorFlow.js. Pokud potřebujete ještě trochu zvýšit přesnost, můžete jej optimalizovat.
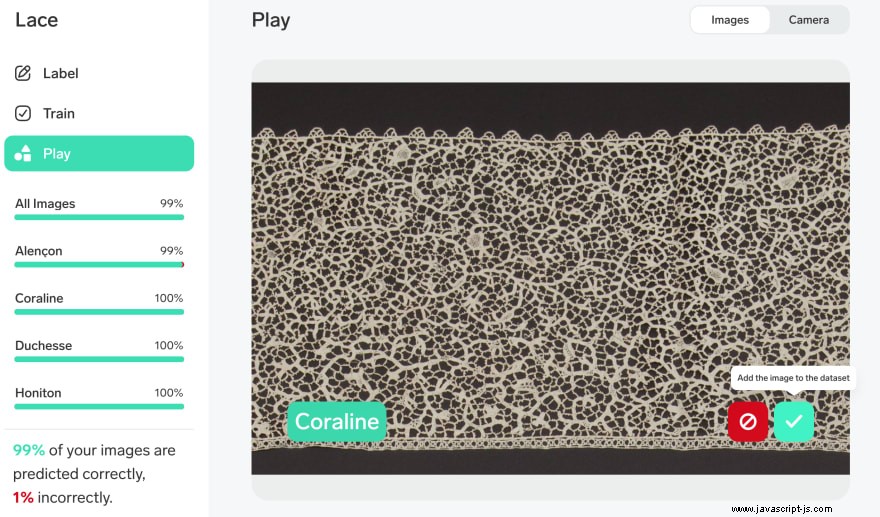
Model se exportuje do složky. Součástí je nějaký ukázkový kód, který můžete smazat (example složka). S největší pravděpodobností existuje mnoho očíslovaných groupx-shard...bin soubory:toto jsou váhy modelu.
Samotný model je obsažen v model.json soubor. Pokud tento soubor otevřete, můžete určit, že se jedná o model ve stylu grafu vygenerovaný TensorFlow a převedený na TensorFlow.js, knihovnu, která umožňuje webovým aplikacím využívat rozhraní API TensorFlow.
Vytvořte si webovou aplikaci pro hostování vašeho modelu
Nyní, když je model vytvořen, testován a stažen, je dalším krokem vytvoření webové aplikace pro jeho hostování. Zatímco modely mohou být velké soubory, které mohou zpomalit spuštění vaší webové aplikace, pokud jsou obzvlášť velké, krása hostování vašeho modelu ve webové aplikaci spočívá v tom, že jej můžete použít offline v kontextu muzea nebo sbírky ke klasifikaci položek. Vaše webová aplikace bude moci běžet na mobilním telefonu a budete moci naskenovat vzorky krajky, abyste si udělali představu o její třídě (pokud spadá do jedné z tříd, ve kterých byl váš model trénován).
Čistým způsobem, jak vytvořit webovou aplikaci, je použití Vue.js, lehkého rámce JavaScriptu, který je zvláště vhodný pro rychlé vytváření webových stránek. Chcete-li spustit Vue.js CLI (rozhraní příkazového řádku) na místním počítači, postupujte podle těchto pokynů k instalaci. Po instalaci vytvořte webovou stránku s názvem 'lacemaking':vue create lacemaking . V nástroji příkazového řádku se vygeneruje řada výzev; postupujte podle těchto doporučení a vytvořte web s výchozím nastavením.
Po dokončení vytváření aplikace zadejte cd lacemaking a poté npm run serve na příkazovém řádku nebo v terminálu a prohlédněte si svůj nový web. Vaše stránky poběží na portu 8080 a můžete je navštívit na adrese http://localhost:8080.
Importujte soubory modelu
Váš web bude mít pouze jednu stránku s tlačítkem pro nahrání obrázku a procesy na pozadí pro zpracování klasifikačních rutin. Otevřete kód, který vaše CLI vytvořilo, pomocí Visual Studio Code.
Nejprve vytvořte složku v public složku s názvem models a v této složce vytvořte složku s názvem lace . Do této složky vložte všechny soubory generované Lobe; důležité jsou všechny soubory shard a model.json . Všechny soubory v public nejsou zpracovávány webovým balíkem, knihovnou, která vytváří vaši aplikaci; chcete, aby byl model obsluhován tak, jak je, nikoli komprimován a žádným způsobem sestavován, takže musí zůstat v nepostavené oblasti.
Dále vezměte signature.json soubor vytvořený Lobe a přesuňte jej do src/assets složku. Tento soubor obsahuje důležité informace o modelu a budete jej používat ve své aplikaci pro různé procesy. Zůstane ve složce aktiv, aby bylo možné je importovat a použít přímo v aplikaci pro informace, které obsahuje.
Připravte aplikaci na TensorFlow nahráním obrázku
Dále nainstalujte TensorFlow.js pomocí npm. Otevřete terminál v kódu Visual Studio výběrem položky Terminál> Nový terminál v editoru kódu. Nainstalujte si také balíček, který pomáhá s nahráváním souborů a spravováním nahrávání snímků z fotoaparátu. V terminálu zadejte:npm install @tensorflow/tfjs a npm install vue-image-upload-resize .
Zkontrolujte package.json soubor, abyste se ujistili, že jsou knihovny nainstalovány v dependencies oblast.
V src/main.js , hlavní soubor aplikace, přidejte na řádek 3 následující řádky:
import ImageUploader from 'vue-image-upload-resize';
Vue.use(ImageUploader);
Tento kód inicializuje knihovnu pro nahrávání. Dále začnete pracovat v components/HelloWorld.vue file, což je Single File Component (SFC) obsahující šablonu pro HTML kód, blok skriptu pro metody JavaScriptu a správu dat a blok stylů pro stylování CSS.
Upravte blok skriptu tak, aby importoval všechny balíčky, které tato aplikace potřebuje, přidáním těchto řádků přímo pod <script> :
import * as tf from "@tensorflow/tfjs";
import signature from "@/assets/signature.json";
const MODEL_URL = "/models/lace/model.json";
Aplikace je nyní připravena používat TensorFlow.js z balíčku TensorFlow, data ze souboru podpisu a model načtený do konstantní proměnné k použití.
V aplikaci použijte TensorFlow.js
Dále přidejte datový objekt pod name řádek v <script> :
data() {
return {
prediction: "",
model: "",
preview: "",
hasImage: false,
alt: '"",
image: null,
outputKey: "Confidences",
classes: signature.classes.Label,
shape: signature.inputs.Image.shape.slice(1, 3),
inputName: signature.inputs.Image.name,
};
},
Tento důležitý blok kódu obsahuje výchozí hodnoty všech proměnných používaných tímto souborem. Zahrnuje zástupný symbol pro předpovědi vrácené modelem, samotný model a data vrácená programem pro nahrávání obrázků. Spravuje také prvky importované prostřednictvím souboru signature.json, zejména pole tříd (Honiton, Point de Venise atd.), které Lobe exportoval. Importuje také parametry tvaru obrázku podpisu.
Za poslední čárku datového objektu přidejte methods objekt, který zahrnuje všechny funkce potřebné k provedení odvození proti modelu:
methods: {
setImage(output) {
this.prediction = "";
this.hasImage = true;
this.preview = output;
},
getImage() {
//step 1, get the image
const image = this.$refs.img1;
let imageTensor = tf.browser.fromPixels(image, 3);
console.log(imageTensor);
this.loadModel(imageTensor);
},
async loadModel(imageTensor) {
//step 2, load model, start inference
this.model = await tf.loadGraphModel(MODEL_URL);
this.predict(imageTensor);
},
dispose() {
if (this.model) {
this.model.dispose();
}
},
predict(image) {
if (this.model) {
const [imgHeight, imgWidth] = image.shape.slice(0, 2);
// convert image to 0-1
const normalizedImage = tf.div(image, tf.scalar(255));
let norm = normalizedImage.reshape([1, ...normalizedImage.shape]);
const reshapedImage = norm;
// center crop and resize
let top = 0;
let left = 0;
let bottom = 1;
let right = 1;
if (imgHeight != imgWidth) {
const size = Math.min(imgHeight, imgWidth);
left = (imgWidth - size) / 2 / imgWidth;
top = (imgHeight - size) / 2 / imgHeight;
right = (imgWidth + size) / 2 / imgWidth;
bottom = (imgHeight + size) / 2 / imgHeight;
}
const croppedImage = tf.image.cropAndResize(
reshapedImage,
[[top, left, bottom, right]],
[0],
[this.shape[0], this.shape[1]]
);
const results = this.model.execute(
{ [this.inputName]: croppedImage },
signature.outputs[this.outputKey].name
);
const resultsArray = results.dataSync();
this.showPrediction(resultsArray);
} else {
console.error("Model not loaded, please await this.load() first.");
}
},
showPrediction(classification) {
//step 3 - classify
let classes = Array.from(this.classes);
let predictions = Array.from(classification).map(function (p, i) {
return {
id: i,
probability: Math.floor(p * 100) + "%",
class: classes[i],
};
});
this.prediction = predictions;
//stop the model inference
this.dispose();
},
},
Zde je několik kroků; při jejich procházení si všimneme, že:
1. Uživatel klikne na tlačítko pro nahrání obrázku a setImage() je nazýván. Výstup tohoto procesu nastavuje preview proměnná, která bude nahraným obrázkem.
2. getImage() se zavolá, jakmile preview byl nastaven na obrazový výstup. Obrázek je vykreslen na obrazovku pomocí odkazu this.$refs.img1 (který přidáte do šablony v dalším kroku). Obrázek je převeden na tenzor pro čtení pomocí TensorFlow pomocí tf.browser.fromPixels API. Poté je model načten a odeslán tento tenzor jako parametr.
3. Vzhledem k tomu, že model je poměrně velký, je loadModel volán asynchronně. Po načtení se spustí proces predikce pomocí tenzoru obrazu.
4. predict() Po načtení modelu je zavolána metoda a obrázek je přečten a přetvořen tak, aby jej model mohl číst ve srozumitelném formátu. Obrázek se vycentruje, ořízne a změní se jeho velikost. Poté se upravený obrázek přivede do modelu a z analýzy obrázku modelem se vygeneruje pole výsledků.
5. Jakmile je z modelu vygenerován výsledek, vytvoří se pole předpovědí s analýzou tříd a jejich pravděpodobnosti zobrazenými a dostupnými pro frontend.
6. Nakonec se model zlikviduje a uvolní se paměť.
Vytvořte rozhraní frontend
Přední část aplikace lze rychle zabudovat do značek šablon. Přepište vše v aktuálních značkách šablony a nahraďte je následujícím označením:
<div>
<h1>Lace Inference</h1>
<img :alt="alt" :src="preview" ref="img1" @load="getImage" />
<div class="uploader">
<image-uploader
:preview="false"
:className="['fileinput', { 'fileinput--loaded': hasImage }]"
capture="environment"
:debug="1"
doNotResize="gif,jpg,jpeg,png"
:autoRotate="true"
outputFormat="string"
@input="setImage"
>
<label for="fileInput" slot="upload-label">
<figure>
<svg
xmlns="http://www.w3.org/2000/svg"
width="32"
height="32"
viewBox="0 0 32 32"
>
<path
class="path1"
d="M9.5 19c0 3.59 2.91 6.5 6.5 6.5s6.5-2.91 6.5-6.5-2.91-6.5-6.5-6.5-6.5 2.91-6.5 6.5zM30 8h-7c-0.5-2-1-4-3-4h-8c-2 0-2.5 2-3 4h-7c-1.1 0-2 0.9-2 2v18c0 1.1 0.9 2 2 2h28c1.1 0 2-0.9 2-2v-18c0-1.1-0.9-2-2-2zM16 27.875c-4.902 0-8.875-3.973-8.875-8.875s3.973-8.875 8.875-8.875c4.902 0 8.875 3.973 8.875 8.875s-3.973 8.875-8.875 8.875zM30 14h-4v-2h4v2z"
></path>
</svg>
</figure>
<span class="upload-caption">{{
hasImage ? "Replace" : "Click to upload"
}}</span>
</label>
</image-uploader>
</div>
<div>
<h2 v-if="prediction != ''">
<span v-for="p in prediction" :key="p.id">
{{ p.class }} {{ p.probability }}<br />
</span>
</h2>
<h2 v-else>
<span v-if="hasImage">Calculating...</span>
</h2>
</div>
</div>
Toto označení zahrnuje:
1. Nástroj pro nahrávání obrázků dostupný prostřednictvím dříve nainstalovaného balíčku npm. Tento nástroj pro nahrávání zavolá setImage() způsob, jak spustit rutinu zpracování obrazu.
2. Zástupný symbol obrázku, kde bude nahraný obrázek zobrazen pro náhled a analýzu pomocí getImage() metoda. Je zabráněno ve změně velikosti obrázku, jak to řeší rutiny změny tvaru.
3. Obrázek SVG kamery, který funguje jako tlačítko a popisek, který se mění v závislosti na tom, zda byl obrázek nahrán nebo ještě nebyl nahrán
4. Oblast pod nástrojem pro nahrávání obrázků pro zobrazení předpovědí. Pokud neexistují žádné předpovědi, zobrazí se zástupný štítek.
Upravte styl aplikace
Nakonec přepište celý blok stylů a přidejte do aplikace několik základních stylů. Tento kód CSS vytvoří skládané rozvržení s obrázkem, tlačítkem a předpovědí.
<style>
#fileInput {
display: none;
}
h1,
h2 {
font-weight: normal;
}
ul {
list-style-type: none;
padding: 0;
}
li {
display: inline-block;
margin: 0 10px;
}
.uploader {
margin-top: 4rem;
margin-bottom: 4rem;
}
</style>
Spusťte a nasaďte aplikaci
Spusťte aplikaci pomocí npm run serve a uvidíte, jak si vede proti různým typům krajky. Pokud model potřebuje více dat nebo potřebuje zlepšit, nebo pokud chcete přidat další třídy, proveďte změny v Lobe. Poté znovu importujte výstupní soubory na jejich správná místa ve vaší webové aplikaci.
Vaše aplikace je nyní připravena k nasazení do produkce, abyste ji mohli používat „ve volné přírodě“, v muzeu nebo soukromé sbírce. Existuje několik možností nasazení aplikace, z nichž mnohé nabízejí bezplatný webhosting. Můžete vyzkoušet Azure Static Web Apps nebo dokonce stránky GitHub, což je dobrá volba a přímo připojené ke kódu GitHubu. Tato řešení předpokládají, že jste svůj kód zavázali ke správě verzí pomocí GitHubu, což budete muset udělat, abyste svou aplikaci nasadili do cloudu.
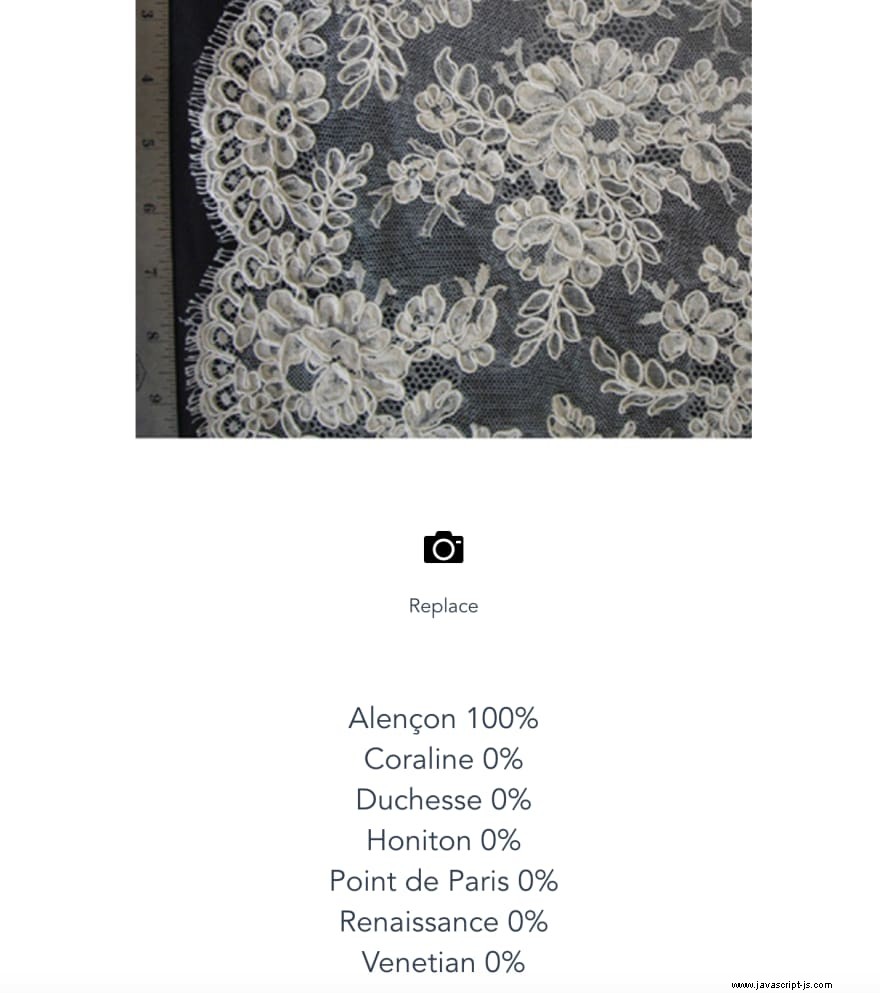
Další kroky
Úspěšně jste vytvořili model strojového učení ke stažení vytvořený pomocí Lobe, což je rychlý způsob, jak lokálně použít přenos učení k vytvoření nástroje pro rozpoznávání obrázků. Vytvořili jste také aplikaci pro hostování modelu a pro použití fotoaparátu ke shromažďování obrazových dat k identifikaci různých typů krajek. Jaké by byly vaše další kroky, abyste dokončili typický kruh strojového učení spočívající v školení, testování, analýze a přeškolování modelu?
Možná budete chtít své modely Lobe, jak jsou znovu vytvořeny z nových dat, připojit ke GitHubu, abyste mohli naplánovat vysílání nového modelu podle plánu s novými daty. Jak váš model roste a vyvíjí se, můžete své návštěvy muzea využít ke shromažďování dalších dat a jejich uložení do zařízení, poté je lokálně předat Lobe a přeškolit model. Postupně můžete přidávat další třídy a vaše webová aplikace je dostatečně flexibilní, aby zvládla jejich přidávání bez nutnosti úprav. Vše, co byste museli udělat, je najít způsob, jak model pravidelně obnovovat, třeba pomocí pracovního postupu GitHub Action, který by byl pravidelně plánován.
Tyto procesy se dotýkají oblasti 'ML Ops' - provozního řízení živých modelů strojového učení. Jako takové jsou mimo rozsah tohoto článku, ale při práci s malou datovou sadou a Lobe můžete vidět příslib vytvoření modelu a pomoci mu vyvinout se. Tímto způsobem rozšíříte jak jeho možnosti, tak své vlastní znalosti o kolekci.
Zdroje
Historie krajky od Palliser, Bury, paní, 1805-1878; Dryden, Alice; Jourdain, Margaret
Krajka a krajkářství v době Vermeer
La Révolte des Passemens , 1935, vydal Klub jehel a paliček Metropolitního muzea umění.