
V posledních několika letech jsme byli svědky toho, že se v komunitě JavaScriptu objevila řada knihoven strojového učení, které vývojářům front-endu umožnily přinést AI na web a řešit složité problémy pomocí snadno použitelných rozhraní API.
TensorFlow je jedna z nejpopulárnějších open-source platforem pro strojové učení, používaná hlavně s Pythonem. V roce 2018 Google oznámil první verzi TensorFlow pro JavaScript s názvem TensorFlow.js. To je to, co prozkoumáme v tomto tutoriálu.
Chystáme se vytvořit klasifikátor obrázků. Na konci tutoriálu bude náš klasifikátor schopen rozlišit obrázky mezi Santou a každodenním starým mužem. Ale abychom mohli začít, musíme nejprve pochopit, co jsou neuronové sítě.
Jak fungují neuronové sítě
Než se ponoříme do kódování, musíme pochopit několik pojmů. Pokud jste již obeznámeni s neuronovými sítěmi, můžete tuto část přeskočit a vrhnout se rovnou na kódování. V opačném případě pokračujte ve čtení, protože budu odkazovat na věci zde uvedené v celém tutoriálu. Nejprve se podívejme, co jsou neuronové sítě?
Neuronové sítě
Zahrnuje mnoho technických záležitostí, ale abychom vám poskytli stručný přehled, neuronové sítě jsou algoritmy strojového učení inspirované biologickými neuronovými sítěmi nalezenými v našem mozku. Používají se k rozpoznávání vzorů a skládají se z uzlů, nazývaných neurony, které jsou vzájemně propojeny synaptickými váhami.
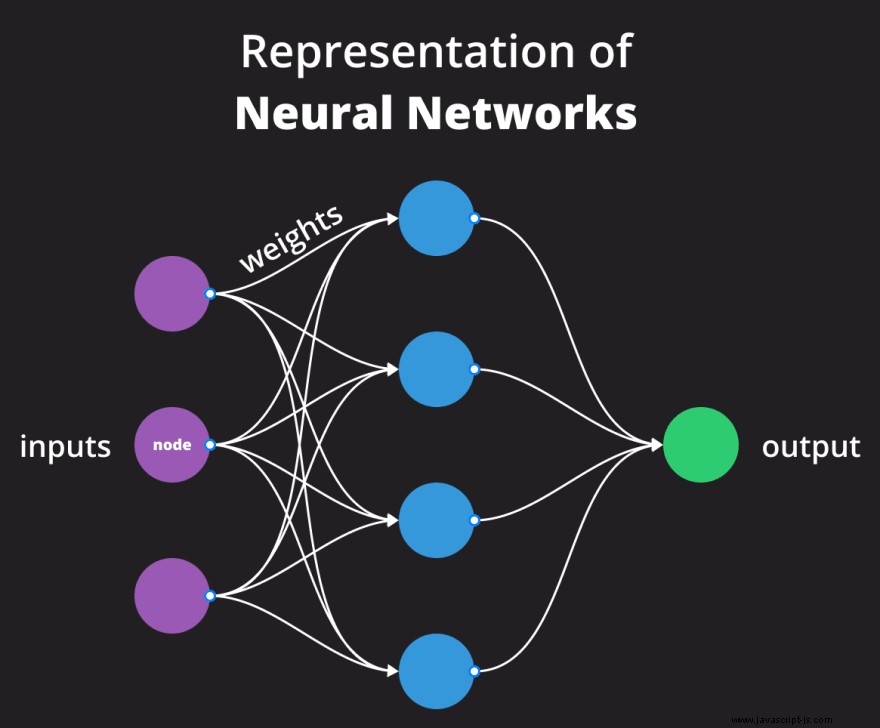
Model
Když jsou tyto algoritmy strojového učení trénovány s daty, získáme model jako výstup. Je to reprezentace tréninkového procesu. Modely lze použít pro předpovědi budoucnosti.
Funkce a štítky
Data, která vkládáte do modelu, se obvykle skládají z prvků a štítků. Funkce jsou atributy spojené s každým vzorkem ve vaší sadě dat. Klasickým příkladem je klasifikace květů Iris na základě znaků, jako je šířka sepalů a okvětních lístků.
Štítky představují, jak byste klasifikovali jednotlivé vzorky. Zůstaňme u příkladu, na základě vlastností kategorizujete vstup do jednoho z volných druhů. Buď dostane označení „Iris setosa“, „Iris virginica“ nebo „Iris versicolor“.
Teď, když máme všechno z cesty, uvidíme, co nakonec budeme mít.
Konečný výstup tohoto kurzu
Na konci tutoriálu budeme mít aplikaci, kterou můžete trénovat na dvou různých sadách obrázků:Santa a starší lidé. Jakmile budete mít dostatek dat, bude aplikace schopna předpovědět, o čem obrázek je, aniž by to kdy viděla.
Celý projekt zpřístupním na CodeSandbox, abyste si s ním mohli vyladit. Odkaz na něj najdete na konci tutoriálu. A pěkný gif o tom, jak bude naše aplikace fungovat:
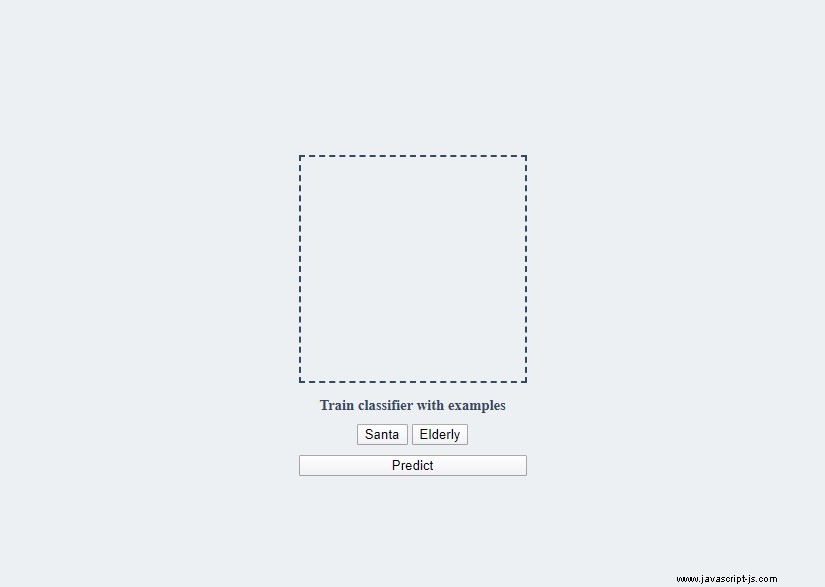
Obrázky můžete přetáhnout na prvek plátna a trénovat klasifikátor kliknutím na jedno z níže uvedených tlačítek. Jakmile budete mít dostatek dat, můžete přetáhnout nový obrázek a předpovědět, co na něm je.
Vtahování závislostí
Náš úplně první krok je natáhnout vše, co potřebujeme. Ke klasifikaci obrázků budeme používat TensorFlow.js a oblíbený předem trénovaný model s názvem MobileNet. Následně použijeme techniku zvanou transfer learning, kdy předtrénovaný model rozšíříme o vlastní tréninkovou sadu na míru. K tomu budeme potřebovat klasifikátor. Budeme používat modul K-nejbližší soused. Umožní nám kategorizovat obrázky a jakmile použijeme predikci, vybere kategorii nejvhodnější pro daný obrázek.
To znamená, že budeme mít 3 závislosti:TensorFlow, MobileNet a modul klasifikátoru KNN. Zde je celý dokument, se kterým budeme pracovat:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Image classification with Tensorflow.js</title>
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<script src="https://unpkg.com/@tensorflow-models/mobilenet"></script>
<script src="https://unpkg.com/@tensorflow-models/knn-classifier"></script>
<link rel="stylesheet" href="styles.css" />
</head>
<body>
<main class="app">
<span class="loading">Loading Model...</span>
<canvas width="224" height="224"></canvas>
<div class="actions">
<span class="info">Train classifier with examples</span>
<button class="santa">Santa</button>
<button class="elderly">Elderly</button>
</div>
<button class="predict">Predict</button>
</main>
<script src="classifier.js"></script>
<script src="ui.js"></script>
</body>
</html>
Před uzavřením těla budeme mít dva různé skripty. Jeden pro klasifikátor a jeden pro práci s událostmi uživatelského rozhraní.
Můžete si také všimnout, že prvek canvas má opravdu specifickou šířku a výšku. Je to proto, že předem trénovaný model byl trénován s obrázky 224x224px. Abychom odpovídali formátu dat, musíme použít stejnou velikost. Stále můžete pracovat s většími obrázky, jen budete muset změnit velikost dat před vložením do klasifikátoru.
Než začneme pracovat na klasifikátoru, pojďme rychle dát dohromady uživatelské rozhraní.
Vytvoření uživatelského rozhraní
Vytvořte nový soubor s názvem ui.js . Uděláme, aby plátno přijímalo obrázky přetažením. Nejprve získejte plátno a jeho kontext a připojte k němu některé posluchače událostí:
const canvas = document.querySelector('canvas');
const context = canvas.getContext('2d');
canvas.addEventListener('dragover', e => e.preventDefault(), false);
canvas.addEventListener('drop', onDrop, false);
Potřebujeme zpracovat dvě události:dragover a drop.onDrop vykreslí obrázek na plátno, zatímco dragover pouze zabrání provedení výchozí akce. To je potřeba, protože bez něj by se obrázek otevřel na stejné kartě.
Bez zabránění výchozí akci se stránka znovu načte
Podívejme se, co je uvnitř onDrop funkce.
const onDrop = (e) => {
e.preventDefault();
const file = e.dataTransfer.files[0];
const reader = new FileReader();
reader.onload = file => {
const img = new Image;
img.onload = () => {
context.drawImage(img, 0, 0, 224, 224);
}
img.src = file.target.result;
}
reader.readAsDataURL(file);
}
Úplně první věcí je zabránit výchozí akci, stejně jako jsme to udělali pro dragover . Dále chceme získat data ze souboru, který jsme umístili na plátno. Můžeme to získat pomocí e.dataTransfer.files[0] . Potom chceme vytvořit nový FileReader objekt a číst soubor jako datovou URL. Chceme také vytvořit funkci pro jeho onload událost. Když reader po načtení souboru vytvoříme nový Image objekt a nastavte jeho zdroj na file.target.result . To bude obsahovat data zakódovaná v base64. A jakmile je obrázek vytvořen, nakreslíme jej na plátno. Pamatujte, že jej musíme změnit na 224x244.
Zde také rychle přidejte posluchače událostí do tlačítek a pak můžeme začít vytvářet klasifikátor. Máme 3 tlačítka a 3 posluchače událostí:
const santaButton = document.querySelector('.santa');
const elderlyButton = document.querySelector('.elderly');
santaButton.addEventListener('click', () => addExample('santa'));
elderlyButton.addEventListener('click', () => addExample('elderly'));
document.querySelector('.predict').addEventListener('click', predict);
Budeme mít addExample funkce, která bude mít jeden parametr:označení pro kategorii. A budeme mít predict funkce.
Vytvoření klasifikátoru
Obě funkce vytvoříme v novém souboru s názvem classifier.js . Nejprve však musíme vytvořit klasifikátor a načíst v MobileNet. Chcete-li to provést, přidejte do classifier.js následující funkci a nazvěte to:
let classifier;
let net;
const loadClassifier = async () => {
classifier = knnClassifier.create();
net = await mobilenet.load();
document.querySelector('.loading').classList.add('hidden');
}
loadClassifier();
Jak klasifikátory, tak model budou použity později. Tak jsem pro ně vytvořil dvě proměnné mimo funkci. Načtení modelu nějakou dobu trvá a dělá to asynchronně, proto používáme async / await . Jakmile se načte, můžeme zprávu o načítání skrýt.

Abychom mohli model rozšířit o vlastní sadu dat, musíme přidat vlastní příklady. Chcete-li to provést, kdykoli uživatel klikne na „Santa“ nebo „Starší“, voláme addExample funkce.
Přidávání příkladů
Funkce provede následující:
- Získejte data obrázku z plátna
- použijte MobileNet k získání funkcí získaných dat
- Trénujte klasifikátor přidáním příkladu s použitím funkcí a souvisejícího štítku
let trainingSets = [0, 0];
const addExample = label => {
const image = tf.browser.fromPixels(canvas);
const feature = net.infer(image, 'conv_preds');
classifier.addExample(feature, label);
context.clearRect(0, 0, canvas.width, canvas.height);
label === 'santa' ?
santaButton.innerText = `Santa (${++trainingSets[0]})` :
elderlyButton.innerText = `Elderly (${++trainingSets[1]})`;
document.querySelector('.info').innerText = `Trained classifier with ${label}`;
image.dispose();
}
Nejprve získáme hodnoty pixelů z plátna pomocí ft.browser.fromPixels . Dále získáme funkce pomocí infer metoda MobileNet. Poté, abychom přidali příklady, můžeme jednoduše zavolat addExample na klasifikátoru s funkcí a štítkem.
Poté musíme aktualizovat prvky DOM. Vyčistíme plátno, takže můžeme přidat nový příklad. Potřebujeme také aktualizovat tlačítka, abychom uživateli řekli, kolik příkladů bylo přidáno do každé sady. Za tímto účelem jsem vytvořil nové pole, které počítá počet příkladů.
Nakonec můžeme zavolat dispose na image pro uvolnění paměti.
Předvídání
Jakmile máme potřebná data, můžeme model otestovat. Kliknutím na „Předpovědět“, predict bude volána funkce, která je velmi podobná addExample :
const predict = async () => {
if (classifier.getNumClasses() > 0) {
const image = tf.browser.fromPixels(canvas);
const feature = net.infer(image, 'conv_preds');
const result = await classifier.predictClass(feature);
context.clearRect(0, 0, canvas.width, canvas.height);
document.querySelector('.info').innerText = `Predicted to be ${result.label}`;
image.dispose();
}
}
Úplně první věcí je otestovat, zda máme příklady v našem souboru dat. Pokud jsme nepřidali žádné příklady, není možné, aby nám to něco předpovědělo. To je to, co classifier.getNumClasses kontroly.
Stejně jako pro addExample , potřebujeme vlastnosti obrázku, které můžeme získat stejným způsobem. Potom musíme zavolat classifier.predictClass předáváním funkcí, abyste získali předpověď o obrázku. Jakmile získáme výsledek, vyčistíme plátno, vytiskneme předpověď a zlikvidujeme image objekt.
Souhrn
A náš klasifikátor obrázků nyní funguje podle očekávání. Po natrénování modelu s několika obrázky pro obě sady můžeme s jistotou předpovědět další obrázek.
Chcete-li získat úplný zdrojový kód a vyladit projekt, navštivte codesandbox.io. Můžete jej také naklonovat z GitHubu. Toto je můj poslední tutoriál pro tento rok, ale v příštím desetiletí se vrátím s novými tématy. Děkuji za přečtení!
Jako poslední slovo bych vám chtěl popřát veselé Vánoce a šťastný nový rok! 🎄 🎉
Zjistěte, jak můžete stavět na klasifikacích a také přidat detekci emocí:
