UPRAVIT: Tato odpověď byla zveřejněna již dávno a htmlDecode funkce zavedla zranitelnost XSS. Byl upraven změnou dočasného prvku z div na textarea snížení šance XSS. Ale v dnešní době bych vám doporučil používat DOMParser API, jak je navrženo v jiné odpovědi.
Používám tyto funkce:
function htmlEncode(value){
// Create a in-memory element, set its inner text (which is automatically encoded)
// Then grab the encoded contents back out. The element never exists on the DOM.
return $('<textarea/>').text(value).html();
}
function htmlDecode(value){
return $('<textarea/>').html(value).text();
}
Element textarea je v podstatě vytvořen v paměti, ale nikdy není připojen k dokumentu.
Na htmlEncode Nastavil jsem funkci innerText prvku a načtěte zakódovaný innerHTML; na htmlDecode Nastavil jsem funkci innerHTML hodnotu prvku a innerText je načteno.
Podívejte se na běžící příklad zde.
Trik jQuery nekóduje uvozovky a v IE vám odstraní mezery.
Na základě úniku templatetag v Django, který je, myslím, již hodně používaný/testovaný, vytvořil jsem tuto funkci, která dělá to, co je potřeba.
Je pravděpodobně jednodušší (a možná i rychlejší) než jakékoli jiné řešení problému s odstraňováním mezer – a kóduje uvozovky, což je nezbytné, pokud chcete výsledek použít například v hodnotě atributu.
function htmlEscape(str) {
return str
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}
// I needed the opposite function today, so adding here too:
function htmlUnescape(str){
return str
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&');
}
Aktualizace 2013-06-17:
Při hledání nejrychlejšího úniku jsem našel tuto implementaci replaceAll metoda:
http://dumpsite.com/forum/index.php?topic=4.msg29#msg29
(také zde odkazováno:Nejrychlejší metoda k nahrazení všech výskytů znaku v řetězci)
Některé výsledky výkonu zde:
http://jsperf.com/htmlencoderegex/25
Poskytuje stejný výsledný řetězec jako vestavěný replace řetězy výše. Byl bych velmi rád, kdyby mi někdo vysvětlil, proč je to rychlejší!?
Aktualizace 2015-03-04:
Právě jsem si všiml, že AngularJS používá přesně výše uvedenou metodu:
https://github.com/angular/angular.js/blob/v1.3.14/src/ngSanitize/sanitize.js#L435
Přidávají několik vylepšení – zdá se, že řeší obskurní problém Unicode a také převádějí všechny nealfanumerické znaky na entity. Měl jsem dojem, že to není nutné, pokud máte pro váš dokument specifikovanou znakovou sadu UTF8.
Podotýkám, že (o 4 roky později) Django stále nedělá ani jednu z těchto věcí, takže si nejsem jistý, jak důležité jsou:
https://github.com/django/django/blob/1.8b1/django/utils/html.py#L44
Aktualizace 2016-04-06:
Můžete také chtít escapovat dopředné lomítko / . Toto není vyžadováno pro správné kódování HTML, ale OWASP to doporučuje jako bezpečnostní opatření proti XSS. (díky @JNF za to, že to navrhl v komentářích)
.replace(/\//g, '/');
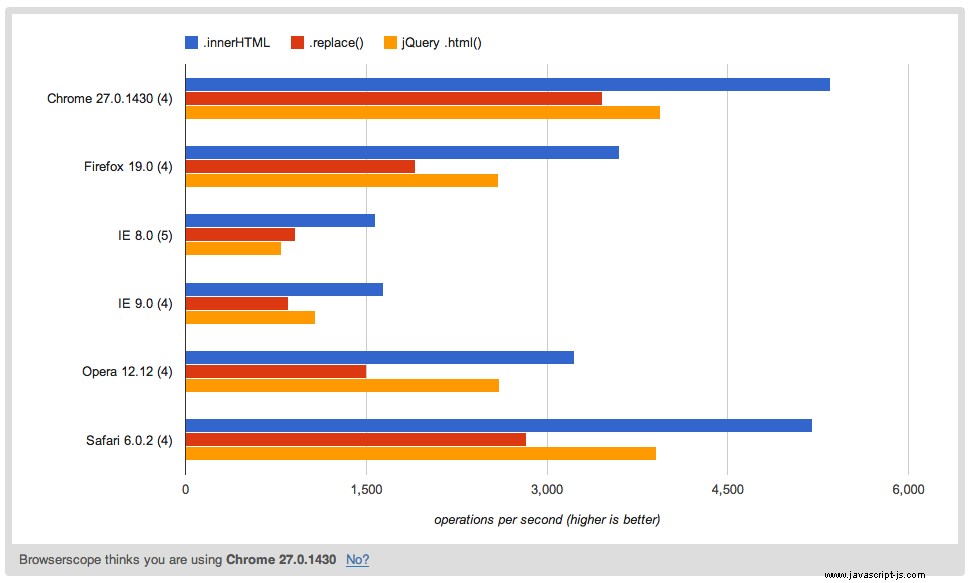
Zde je verze bez jQuery, která je podstatně rychlejší než obě verze jQuery .html() verze a .replace() verze. Tím se zachovají všechny mezery, ale stejně jako verze jQuery nezpracovává uvozovky.
function htmlEncode( html ) {
return document.createElement( 'a' ).appendChild(
document.createTextNode( html ) ).parentNode.innerHTML;
};
Rychlost: http://jsperf.com/htmlencoderegex/17
Ukázka: 
Výstup:
Skript:
function htmlEncode( html ) {
return document.createElement( 'a' ).appendChild(
document.createTextNode( html ) ).parentNode.innerHTML;
};
function htmlDecode( html ) {
var a = document.createElement( 'a' ); a.innerHTML = html;
return a.textContent;
};
document.getElementById( 'text' ).value = htmlEncode( document.getElementById( 'hidden' ).value );
//sanity check
var html = '<div> & hello</div>';
document.getElementById( 'same' ).textContent =
'html === htmlDecode( htmlEncode( html ) ): '
+ ( html === htmlDecode( htmlEncode( html ) ) );
HTML:
<input id="hidden" type="hidden" value="chalk & cheese" />
<input id="text" value="" />
<div id="same"></div>