Tato esej byla inspirována sérií knih Kylea Simpsona You Don’t Know JavaScript . Jsou dobrým začátkem se základy JavaScriptu. Node je většinou JavaScript s výjimkou několika rozdílů, které v této eseji zdůrazním. Kód se nachází v uzlu You Don’t Know Node Úložiště GitHub pod code složka.
Proč se starat o Node? Node je JavaScript a JavaScript je téměř všude! Co když může být svět lepším místem, když Node zvládne více vývojářů? Lepší aplikace rovná se lepší život!
Jedná se o kuchyňský dřez subjektivně nejzajímavějších základních vlastností. Klíčové poznatky této eseje jsou:
- Smyčka událostí:Obohacení základního konceptu, který umožňuje neblokování I/O
- Globální a procesní:Jak získat více informací
- Emitory událostí:Kurz nárazu ve vzoru založeném na událostech
- Streamy a vyrovnávací paměti:Efektivní způsob práce s daty
- Clustery:Rozdělte procesy jako profesionál
- Zpracování asynchronních chyb:AsyncWrap, Domain a uncaughtException
- Doplňky C++:Přispívání k jádru a psaní vlastních doplňků C++
Smyčka událostí
Můžeme začít se smyčkou událostí, která je jádrem Node.
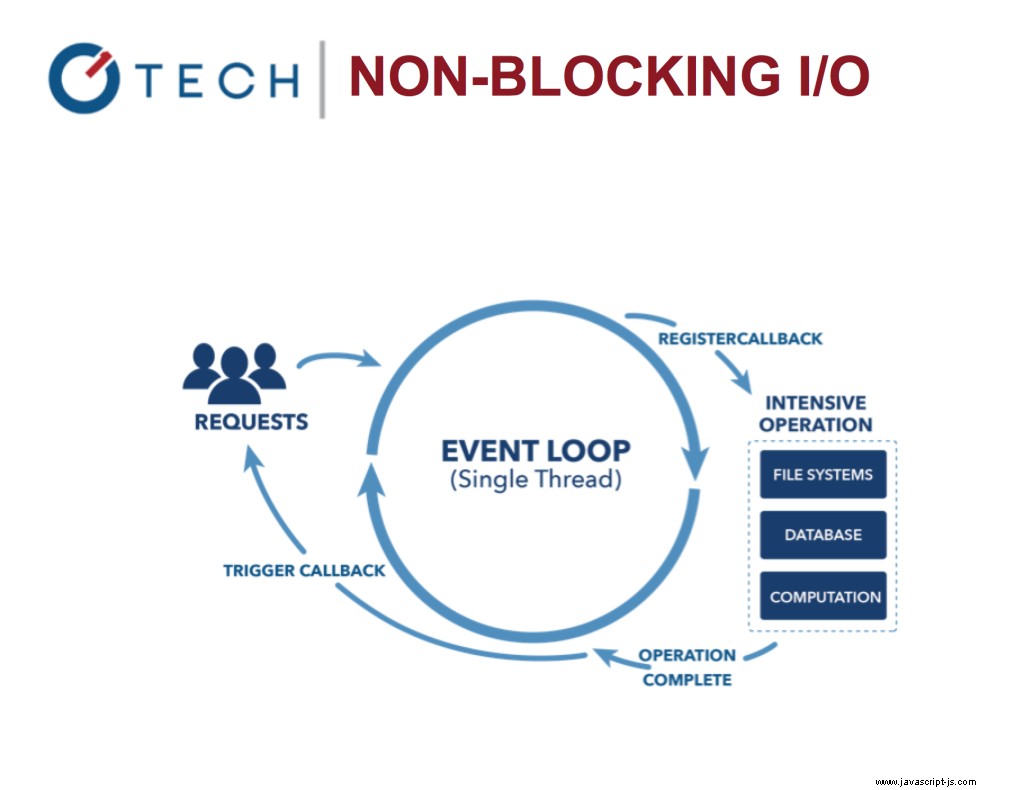
Node.js Neblokující I/O
Umožňuje zpracování dalších úloh, zatímco jsou v procesu IO volání. Myslete na Nginx vs. Apache. Umožňuje, aby byl Node velmi rychlý a efektivní, protože blokování I/O je drahé!
Podívejte se na tento základní příklad zpožděného println funkce v Javě:
System.out.println("Step: 1");
System.out.println("Step: 2");
Thread.sleep(1000);
System.out.println("Step: 3");
Je srovnatelný (ale ne ve skutečnosti) s tímto kódem uzlu:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
}, 1000)
console.log('Step: 2')
Není to však úplně stejné. Musíte začít myslet asynchronně. Výstup skriptu Node je 1, 2, 3, ale pokud bychom měli po „kroku 2“ více příkazů, byly by provedeny před zpětným voláním setTimeout . Podívejte se na tento úryvek:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
console.log('Step 5')
}, 1000);
console.log('Step: 2')
console.log('Step 4')
Vytváří 1, 2, 4, 3, 5. Je to proto, že setTimeout vkládá zpětné volání do budoucích cyklů smyčky událostí.
Přemýšlejte o smyčce událostí jako vždy, když se točí smyčka jako for nebo while smyčka. Zastaví se pouze v případě, že nyní ani v budoucnu není co spustit.
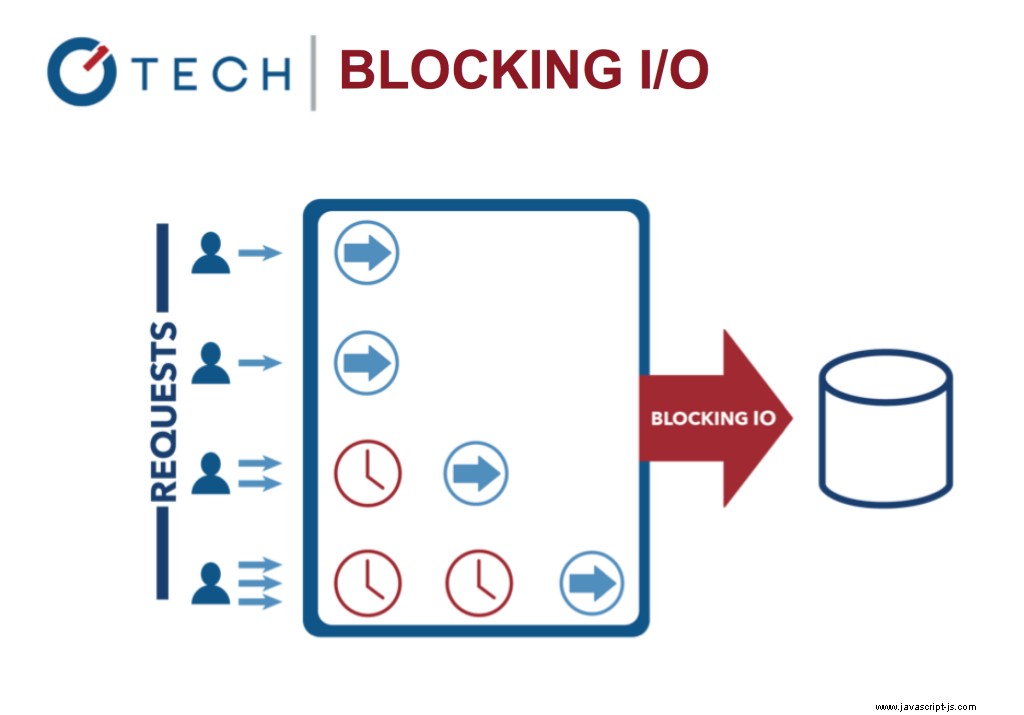
Blokování I/O:Multi-Threading Java
Smyčka událostí umožňuje systémům být efektivnější, protože nyní můžete dělat více věcí, zatímco čekáte na dokončení své drahé vstupní/výstupní úlohy.
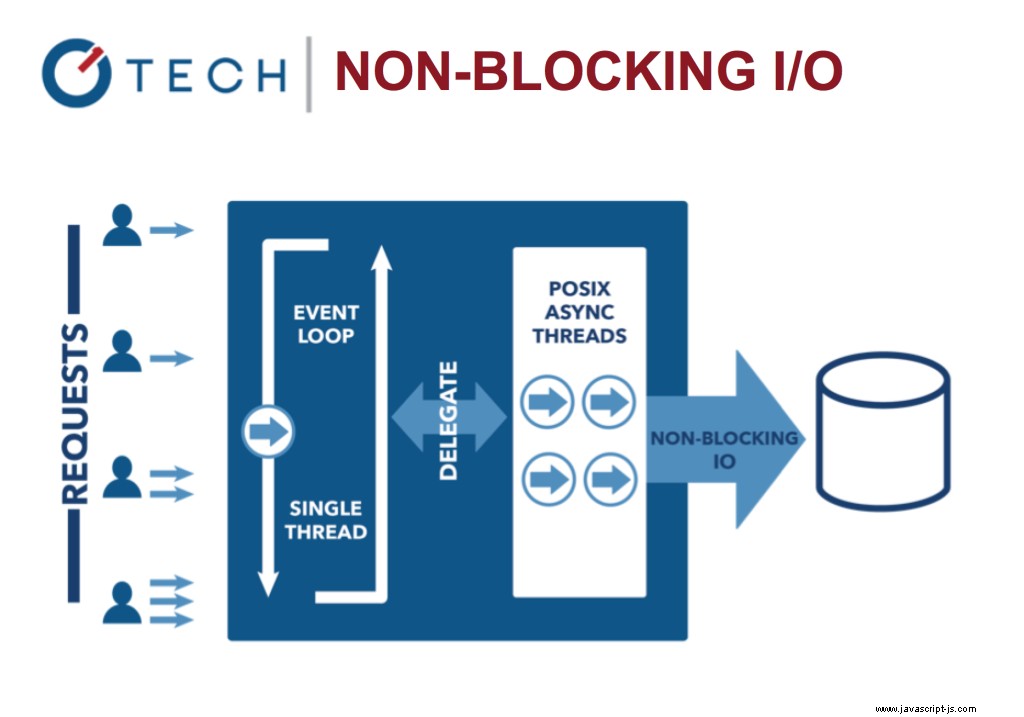
Neblokující I/O:Node.js
To je v kontrastu s dnešním běžnějším modelem souběžnosti, kde se používají vlákna OS. Síťování založené na vláknech je relativně neefektivní a velmi obtížně použitelné. Uživatelé Node se navíc nemusí starat o zablokování procesu – neexistují žádné zámky.
Rychlá poznámka na okraj:V Node.js je stále možné psát blokovací kód. ? Zvažte tento jednoduchý, ale blokující kód Node.js:
console.log('Step: 1')
var start = Date.now()
for (var i = 1; i<1000000000; i++) {
// This will take 100-1000ms depending on your machine
}
var end = Date.now()
console.log('Step: 2')
console.log(end-start)
Většinu času samozřejmě v našem kódu nemáme prázdné smyčky. Odhalit synchronní a tím blokující kód může být obtížnější při použití modulů jiných lidí. Například jádro fs (systém souborů) modul přichází se dvěma sadami metod. Každý pár plní stejné funkce, ale jiným způsobem. Blokuje se fs Metody Node.js, které mají slovo Sync v jejich jménech:
[Sidenote]
Čtení blogových příspěvků je dobré, ale sledování videokurzů je ještě lepší, protože jsou poutavější.
Mnoho vývojářů si stěžovalo, že na Node je nedostatek dostupného kvalitního videomateriálu. Sledování videí na YouTube je rušivé a platit 500 $ za videokurz Node je šílené!
Jděte se podívat na Node University, která má na Node ZDARMA videokurzy:node.university.
[Konec vedlejší poznámky]
var fs = require('fs')
var contents = fs.readFileSync('accounts.txt','utf8')
console.log(contents)
console.log('Hello Ruby\n')
var contents = fs.readFileSync('ips.txt','utf8')
console.log(contents)
console.log('Hello Node!')
Výsledky jsou velmi předvídatelné i pro nové uživatele Node/JavaScript:
data1->Hello Ruby->data2->Hello NODE!
Věci se změní, když přejdeme na asynchronní metody. Toto je neblokující kód Node.js:
var fs = require('fs');
var contents = fs.readFile('accounts.txt','utf8', function(err,contents){
console.log(contents);
});
console.log('Hello Python\n');
var contents = fs.readFile('ips.txt','utf8', function(err,contents){
console.log(contents);
});
console.log("Hello Node!");
Vytiskne obsah jako poslední, protože jejich provedení bude nějakou dobu trvat, jsou ve zpětných voláních. Smyčky událostí se k nim dostanou, když čtení souboru skončí:
Hello Python->Hello Node->data1->data2
Smyčka událostí a neblokující I/O jsou tedy velmi výkonné, ale musíte kódovat asynchronně, což není způsob, jakým se většina z nás naučila kódovat ve školách.
Globální
Při přechodu na Node.js z prohlížeče JavaScript nebo jiného programovacího jazyka vyvstávají tyto otázky:
- Kam ukládat hesla?
- Jak vytvořit globální proměnné (ne
windowv Node)? - Jak získat přístup ke vstupu CLI, operačnímu systému, platformě, využití paměti, verzím atd.?
Existuje globální objekt. Má určité vlastnosti. Některé z nich jsou následující:
global.process:Proces, systém, informace o prostředí (máte přístup ke vstupu CLI, proměnným prostředí pomocí hesel, paměti atd.)global.__filename:Název souboru a cesta k aktuálně spuštěnému skriptu, kde je tento příkazglobal.__dirname:Absolutní cesta k aktuálně spuštěnému skriptuglobal.module:Objekt pro export kódu, čímž se tento soubor stane modulemglobal.require():Metoda importu modulů, souborů JSON a složek
Pak tu máme obvyklé podezřelé metody z JavaScriptu prohlížeče:
global.console()global.setInterval()global.setTimeout()
Ke každé z globálních vlastností lze přistupovat s velkým názvem GLOBAL nebo zcela bez jmenného prostoru, např. process místo global.process .
Proces
Process object má spoustu informací, takže si zaslouží vlastní sekci. Uvedu pouze některé vlastnosti:
process.pid:ID procesu této instance uzluprocess.versions:Různé verze Node, V8 a dalších komponentprocess.arch:Architektura systémuprocess.argv:Argumenty CLIprocess.env:Proměnné prostředí
Některé z metod jsou následující:
process.uptime():Získejte dostupnostprocess.memoryUsage():Získejte využití pamětiprocess.cwd():Získejte aktuální pracovní adresář. Nezaměňovat s__dirnamecož nezávisí na místě, ze kterého byl proces spuštěn.process.exit():Ukončení aktuálního procesu. Můžete zadat kód jako 0 nebo 1.process.on():Připojte posluchač události, např. `on(‘uncaughtException’)
Těžká otázka:Kdo má rád zpětná volání a rozumí jim? ?
Někteří lidé příliš milují zpětná volání, a tak vytvořili http://callbackhell.com. Pokud tento termín ještě neznáte, zde je ilustrace:
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
Callback hell se špatně čte a je náchylný k chybám. Jak modularizujeme a organizujeme asynchronní kód, kromě zpětných volání, která nejsou příliš vývojově škálovatelná?
Emitenty událostí
Na pomoc s peklem zpětného volání nebo pyramidou zkázy jsou zde emitory událostí. Umožňují implementovat váš asynchronní kód pomocí událostí.
Jednoduše řečeno, emitor události je něco, co spouští událost, kterou může poslouchat kdokoli. V node.js lze událost popsat jako řetězec s odpovídajícím zpětným voláním.
Emitory událostí slouží k těmto účelům:
- Zpracování událostí v Node používá vzor pozorovatele
- Událost nebo předmět sleduje všechny funkce, které jsou s ní spojeny
- Tyto související funkce, známé jako pozorovatelé, se provádějí při spuštění dané události
Chcete-li použít emitory událostí, importujte modul a vytvořte instanci objektu:
var events = require('events')
var emitter = new events.EventEmitter()
Poté můžete připojit posluchače událostí a spouštět/vysílat události:
emitter.on('knock', function() {
console.log('Who\'s there?')
})
emitter.on('knock', function() {
console.log('Go away!')
})
emitter.emit('knock')
Pojďme udělat něco užitečnějšího s EventEmitter přejímáním z něj. Představte si, že máte za úkol implementovat třídu, která bude provádět měsíční, týdenní a denní e-mailové úlohy. Třída musí být dostatečně flexibilní, aby si vývojáři mohli přizpůsobit konečný výstup. Jinými slovy, kdokoli používá tuto třídu, musí být schopen vložit nějakou vlastní logiku, když úloha skončí.
Níže uvedený diagram vysvětluje, co zdědíme z modulu událostí, abychom vytvořili Job a poté použijte done posluchač událostí pro přizpůsobení chování Job třída:

Node.js Event Emitters:Observer Pattern
Třída Job si zachová své vlastnosti, ale získá také události. Vše, co potřebujeme, je spustit done až proces skončí:
// job.js
var util = require('util')
var Job = function Job() {
var job = this
// ...
job.process = function() {
// ...
job.emit('done', { completedOn: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter)
module.exports = Job
Nyní je naším cílem přizpůsobit chování Job na konci úkolu. Protože vysílá done , můžeme připojit posluchač události:
// weekly.js
var Job = require('./job.js')
var job = new Job()
job.on('done', function(details){
console.log('Job was completed at', details.completedOn)
job.removeAllListeners()
})
job.process()
Vysílač má více funkcí:
emitter.listeners(eventName):Seznam všech posluchačů události pro danou událostemitter.once(eventName, listener):Připojte posluchač události, který se spustí pouze jednou.emitter.removeListener(eventName, listener):Odebrání posluchače události.
Vzor událostí se používá v celém Node a zejména v jeho základních modulech. Z tohoto důvodu vám mastering událostí poskytne skvělou příležitost pro váš čas.
Streamy
Při práci s velkými daty v Node dochází k několika problémům. Rychlost může být pomalá a limit vyrovnávací paměti je ~1Gb. Také, jak pracujete, pokud je zdroj nepřetržitý a nikdy nebyl navržen tak, aby skončil? Chcete-li tyto problémy vyřešit, použijte streamy.
Toky uzlů jsou abstrakce pro nepřetržité rozdělování dat. Jinými slovy, není třeba čekat na načtení celého zdroje. Podívejte se na níže uvedený diagram, který ukazuje standardní přístup s vyrovnávací pamětí:

Přístup k vyrovnávací paměti Node.js
Než můžeme začít zpracovávat a/nebo vydávat, musíme počkat, až se načte celý buffer. Nyní to porovnejte s dalším diagramem zobrazujícím proudy. V něm můžeme zpracovávat data a/nebo je rovnou vydávat, od prvního bloku:

Node.js Stream Approach
V Node máte čtyři typy streamů:
- Čitelné:Můžete z nich číst
- Zapisovatelný:Můžete jim psát
- Duplex:Můžete číst a psát
- Transformovat:Používáte je k transformaci dat
Streamy jsou v Node prakticky všude. Nejpoužívanější implementace streamu jsou:
- Požadavky a odpovědi HTTP
- Standardní vstup/výstup
- Soubor čte a zapisuje
Toky dědí z objektu Emitor události a poskytují vzor pozorovatele, tj. události. Pamatujete si je? Můžeme to použít k implementaci streamů.
Příklad čitelného streamu
Příklad čitelného streamu může být process.stdin což je standardní vstupní proud. Obsahuje data vstupující do aplikace. Vstup obvykle pochází z klávesnice použité ke spuštění procesu.
Chcete-li číst data z stdin , použijte data a end Události. data zpětné volání události bude mít chunk jako jeho argument:
process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})
Takže chunk je pak vstup vložen do programu. V závislosti na velikosti vstupu se tato událost může spustit vícekrát. end událost je nezbytná pro signalizaci ukončení vstupního proudu.
Poznámka:stdin je ve výchozím nastavení pozastaveno a musí být obnoveno, než z něj bude možné číst data.
Čitelné streamy mají také read() rozhraní, které pracuje synchronně. Vrátí chunk nebo null když stream skončí. Můžeme použít toto chování a dát null !== (chunk = readable.read()) do while podmínka:
var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})
V ideálním případě chceme v Node co nejvíce psát asynchronní kód, abychom se vyhnuli blokování vlákna. Datové bloky jsou však malé, takže se nemusíme starat o blokování vlákna pomocí synchronního readable.read() .
Příklad streamu s možností zápisu
Příkladem zapisovatelného streamu je process.stdout . Standardní výstupní toky obsahují data vycházející z aplikace. Vývojáři mohou zapisovat do streamu pomocí write operace.
process.stdout.write('A simple message\n')
Data zapsaná na standardní výstup jsou na příkazovém řádku viditelná stejně jako když použijeme console.log() .
Potrubí
Node poskytuje vývojářům alternativu k událostem. Můžeme použít pipe() metoda. Tento příklad čte ze souboru, komprimuje jej pomocí GZip a zapisuje komprimovaná data do souboru:
var r = fs.createReadStream('file.txt')
var z = zlib.createGzip()
var w = fs.createWriteStream('file.txt.gz')
r.pipe(z).pipe(w)
Readable.pipe() vezme zapisovatelný stream a vrátí cíl, proto můžeme řetězit pipe() metody jedna po druhé.
Při použití streamů tedy máte na výběr mezi událostmi a kanály.
Streamy HTTP
Většina z nás používá Node k vytváření webových aplikací buď tradičních (think server) nebo RESTful APi (think client). Jak je to tedy s HTTP požadavkem? Můžeme to streamovat? Odpověď zní jednoznačně ano .
Požadavek a odpověď jsou čitelné a zapisovatelné toky a dědí se od emitorů událostí. Můžeme připojit data posluchač události. V jeho zpětném volání obdržíme chunk , můžeme jej transformovat hned, aniž bychom čekali na celou odpověď. V tomto příkladu zřetězuji body a analyzovat jej ve zpětném volání end událost:
const http = require('http')
var server = http.createServer( (req, res) => {
var body = ''
req.setEncoding('utf8')
req.on('data', (chunk) => {
body += chunk
})
req.on('end', () => {
var data = JSON.parse(body)
res.write(typeof data)
res.end()
})
})
server.listen(1337)
Poznámka:()=>{} je syntaxe ES6 pro funkce tlustých šipek, zatímco const je nový operátor. Pokud ještě nejste obeznámeni s funkcemi a syntaxí ES6/ES2015, přečtěte si článek
Nejlepších 10 funkcí ES6, které musí znát každý zaneprázdněný vývojář JavaScript .
Nyní přiblížíme náš server příkladu ze skutečného života pomocí Express.js. V tomto dalším příkladu mám obrovský obrázek (~8 Mb) a dvě sady expresních tras:/stream a /non-stream .
server-stream.js:
app.get('/non-stream', function(req, res) {
var file = fs.readFile(largeImagePath, function(error, data){
res.end(data)
})
})
app.get('/stream', function(req, res) {
var stream = fs.createReadStream(largeImagePath)
stream.pipe(res)
})
Mám také alternativní implementaci s událostmi v /stream2 a synchronní implementace v /non-stream2 . Dělají totéž, pokud jde o streamování nebo nestreamování, ale s jinou syntaxí a stylem. Synchronní metody jsou v tomto případě výkonnější, protože posíláme pouze jeden požadavek, nikoli souběžné požadavky.
Chcete-li spustit příklad, spusťte ve svém terminálu:
$ node server-stream
Poté v prohlížeči Chrome otevřete http://localhost:3000/stream a http://localhost:3000/non-stream. Karta Network v DevTools vám zobrazí záhlaví. Porovnejte X-Response-Time . V mém případě to bylo o řád nižší pro /stream a /stream2 :300 ms vs. 3–5 s.
Váš výsledek se bude lišit, ale myšlenka je, že se streamem začnou uživatelé/klienti získávat data dříve. Node streamy jsou opravdu mocné! Existuje několik dobrých zdrojů pro streamování, abyste je zvládli a stali se ve svém týmu expertem na streamy.
[Stream Handbook](https://github.com/substack/stream-handbook] a stream-adventure, které si můžete nainstalovat pomocí npm:
$ sudo npm install -g stream-adventure
$ stream-adventure
Vyrovnávací paměti
Jaký datový typ můžeme použít pro binární data? Pokud si pamatujete, JavaScript prohlížeče nemá binární datový typ, ale Node ano. Říká se tomu buffer. Je to globální objekt, takže jej nemusíme importovat jako modul.
Chcete-li vytvořit binární datový typ, použijte jeden z následujících příkazů:
Buffer.alloc(size)Buffer.from(array)Buffer.from(buffer)Buffer.from(str[, encoding])
Oficiální dokumenty Buffer uvádějí všechny metody a kódování. Nejoblíbenější kódování je utf8 .
Typický buffer bude vypadat jako blábol, takže ho musíme převést na řetězec s toString() mít formát čitelný pro člověka. for smyčka vytvoří vyrovnávací paměť s abecedou:
let buf = Buffer.alloc(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97 // 97 is ASCII a
}
Vyrovnávací paměť bude vypadat jako pole čísel, pokud ji nepřevedeme na řetězec:
console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
A můžeme použít toString převést vyrovnávací paměť na řetězec.
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz
Pokud potřebujeme pouze podřetězec, metoda přijímá počáteční číslo a koncové pozice:
buf.toString('ascii', 0, 5) // outputs: abcde
buf.toString('utf8', 0, 5) // outputs: abcde
buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcde
Pamatujete si fs? Ve výchozím nastavení data hodnota je také buffer:
fs.readFile('/etc/passwd', function (err, data) {
if (err) return console.error(err)
console.log(data)
});
data je buffer při práci se soubory.
Shluky
Často můžete slyšet argument od skeptiků Node, že je to jednovláknové, a proto se nebude škálovat. Je zde základní modul cluster (to znamená, že jej nemusíte instalovat; je součástí platformy), což vám umožní využít veškerý výkon procesoru každého počítače. To vám umožní vertikálně škálovat programy Node.
Kód je velmi snadný. Potřebujeme importovat modul, vytvořit jednoho mastera a více pracovníků. Obvykle vytváříme tolik procesů, kolik máme CPU. Není to pravidlo vytesané do kamene. Můžete mít tolik nových procesů, kolik chcete, ale v určitém bodě se aktivuje zákon klesající návratnosti a nedosáhnete žádného zlepšení výkonu.
Kód pro master a worker je ve stejném souboru. Pracovník může poslouchat na stejném portu a poslat zprávu (prostřednictvím událostí) masteru. Master může naslouchat událostem a restartovat clustery podle potřeby. Způsob, jak napsat kód pro master, je použít cluster.isMaster() a pro pracovníka je to cluster.isWorker() . Většina serverového kódu bude umístěna v pracovníkovi (isWorker() ).
// cluster.js
var cluster = require('cluster')
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
// your server code
})
V cluster.js například můj server vydává ID procesů, takže vidíte, že různí pracovníci zpracovávají různé požadavky. Je to jako vyvažovač zatížení, ale není to skutečný vyvažovač zatížení, protože zatížení nebude rozloženo rovnoměrně. Můžete vidět mnohem více požadavků připadajících na jeden proces (PID bude stejné).
Chcete-li vidět, že různí pracovníci obsluhují různé požadavky, použijte loadtest což je nástroj pro testování zátěže (nebo zátěže) založený na uzlech:
- Nainstalujte
loadtests npm:$ npm install -g loadtest - Spusťte
code/cluster.jss uzlem ($ node cluster.js); ponechat server spuštěný - Spusťte zátěžové testování s:
$ loadtest http://localhost:3000 -t 20 -c 10v novém okně - Analyzujte výsledky jak na serverovém terminálu, tak na
loadtestterminál - Po dokončení testování stiskněte na terminálu serveru control+c. Měli byste vidět různé PID. Zapište si počet vyřízených požadavků.
-t 20 -c 10 v loadtest příkaz znamená, že bude 10 souběžných požadavků a maximální doba je 20 sekund.
Cluster jádra je součástí jádra a to je v podstatě jeho jediná výhoda. Až budete připraveni na nasazení do produkce, možná budete chtít použít pokročilejšího správce procesů:
strong-cluster-control(https://github.com/strongloop/strong-cluster-control), nebo$ slc run:dobrá volbapm2(https://github.com/Unitech/pm2):dobrá volba
odpoledne
Pojďme se zabývat pm2 nástroj, který je jedním ze způsobů, jak vertikálně škálovat vaši aplikaci Node (jeden z nejlepších způsobů), a také mít určitý výkon a funkce na úrovni produkce.
Stručně řečeno, pm2 má tyto výhody:
- Load-balancer a další funkce
- Doba opětovného načítání 0s, tj. navždy naživu
- Dobré pokrytí testem
Dokumenty pm2 najdete na https://github.com/Unitech/pm2 a http://pm2.keymetrics.io.
Podívejte se na tento Express server (server.js ) jako příklad pm2. Neexistuje žádný standardní kód isMaster() což je dobré, protože nemusíte upravovat zdrojový kód, jako jsme to udělali u cluster . Vše, co na tomto serveru děláme, je logpid a udržovat o nich statistiky.
var express = require('express')
var port = 3000
global.stats = {}
console.log('worker (%s) is now listening to http://localhost:%s',
process.pid, port)
var app = express()
app.get('*', function(req, res) {
if (!global.stats[process.pid]) global.stats[process.pid] = 1
else global.stats[process.pid] += 1;
var l ='cluser '
+ process.pid
+ ' responded \n';
console.log(l, global.stats)
res.status(200).send(l)
})
app.listen(port)
Chcete-li spustit tento pm2 například použijte pm2 start server.js . Můžete předat počet instancí/procesů, které se mají vytvořit (-i 0 znamená tolik jako počet CPU, což jsou v mém případě 4) a možnost přihlášení do souboru (-l log.txt ):
$ pm2 start server.js -i 0 -l ./log.txt

Další pěkná věc na pm2 je, že jde do popředí. Chcete-li zjistit, co aktuálně běží, spusťte:
$ pm2 list
Poté použijte loadtest jako jsme to udělali v jádru cluster příklad. V novém okně spusťte tyto příkazy:
$ loadtest http://localhost:3000 -t 20 -c 10
Vaše výsledky se mohou lišit, ale dostávám víceméně rovnoměrně rozložené výsledky v log.txt :
cluser 67415 responded
{ '67415': 4078 }
cluser 67430 responded
{ '67430': 4155 }
cluser 67404 responded
{ '67404': 4075 }
cluser 67403 responded
{ '67403': 4054 }
Spawn vs Fork vs Exec
Protože jsme použili fork() v cluter.js například pro vytvoření nových instancí serverů Node, stojí za zmínku, že existují tři způsoby, jak spustit externí proces z Node.js. Jsou spawn() , fork() a exec() a všechny tři pocházejí z jádra child_process modul. Rozdíly lze shrnout v následujícím seznamu:
require('child_process').spawn():Používá se pro velká data, podporuje streamy, lze jej použít s libovolnými příkazy a nevytváří novou instanci V8require('child_process').fork()– Vytvoří novou instanci V8, vytvoří instanci více pracovníků a funguje pouze se skripty Node.js (nodepříkaz)require('child_process').exec()– Používá vyrovnávací paměť, díky které je nevhodný pro velká data nebo streamování, funguje asynchronně, aby vám při zpětném volání získala všechna data najednou, a lze jej použít s jakýmkoli příkazem, nejennode
Podívejme se na tento příklad spawnu, ve kterém spustíme node program.js , ale příkaz může spustit bash, Python, Ruby nebo jakékoli jiné příkazy nebo skripty. Pokud potřebujete příkazu předat další argumenty, jednoduše je vložte jako argumenty pole, což je parametr spawn() . Data přicházejí jako stream v data obsluha události:
var fs = require('fs')
var process = require('child_process')
var p = process.spawn('node', 'program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
Z pohledu node program.js příkaz, data je jeho standardní výstup; tj. výstup terminálu z node program.js .
Syntaxe pro fork() je nápadně podobný spawn() s jednou výjimkou, neexistuje žádný příkaz, protože fork() předpokládá, že všechny procesy jsou Node.js:
var fs = require('fs')
var process = require('child_process')
var p = process.fork('program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
Posledním bodem našeho programu v této sekci je exec() . Je to trochu jiné, protože nepoužívá vzor události, ale jediné zpětné volání. V něm máte parametry error, standardní výstup a standardní chybové parametry:
var fs = require('fs')
var process = require('child_process')
var p = process.exec('node program.js', function (error, stdout, stderr) {
if (error) console.log(error.code)
})
Rozdíl mezi error a stderr je, že první pochází z exec() (např. oprávnění odepřeno pro program.js ), zatímco druhý z chybového výstupu příkazu, který spouštíte (např. připojení k databázi selhalo do program.js ).
Zpracování asynchronních chyb
Když už mluvíme o chybách, v Node.js a téměř ve všech programovacích jazycích máme try/catch které používáme k řešení chyb. U synchronních chyb funguje pokus/chytit dobře.
try {
throw new Error('Fail!')
} catch (e) {
console.log('Custom Error: ' + e.message)
}
Moduly a funkce vyvolávají chyby, které zachytíme později. Toto funguje v Javě a synchronně Uzel. Nejlepším postupem pro Node.js je však psát asynchronní kódu, abychom vlákno neblokovali.
Smyčka událostí je mechanismus, který umožňuje systému delegovat a plánovat kód, který je třeba provést v budoucnu, až budou dokončeny nákladné vstupní/výstupní úlohy. Problém nastává u asynchronních chyb, protože systém ztrácí kontext chyby.
Například setTimeout() funguje asynchronně naplánováním zpětného volání v budoucnu. Je to podobné asynchronní funkci, která vytváří požadavek HTTP, čte z databáze nebo zapisuje do souboru:
try {
setTimeout(function () {
throw new Error('Fail!')
}, Math.round(Math.random()*100))
} catch (e) {
console.log('Custom Error: ' + e.message)
}
Neexistuje žádné try/catch při provedení zpětného volání a pádu aplikace. Samozřejmě, pokud vložíte další try/catch ve zpětném volání zachytí chybu, ale to není dobré řešení. Tyto otravné asynchronní chyby se obtížněji zvládají a ladí. Try/catch není pro asynchronní kód dost dobrý.
Takže asynchronní chyby zhroutí naše aplikace. Jak s nimi naložíme? ? Už jste viděli, že existuje error argument ve většině zpětných volání. Vývojáři to musí zkontrolovat a probublávat (předat řetězec zpětného volání nebo odeslat uživateli chybovou zprávu) při každém zpětném volání:
if (error) return callback(error)
// or
if (error) return console.error(error)
Další doporučené postupy pro zpracování asynchronních chyb jsou následující:
- Poslouchejte všechny události „při chybě“
- Poslouchejte
uncaughtException - Použijte
domain(soft deprecated) nebo AsyncWrap - Login, log, log &Trace
- Upozornit (volitelné)
- Ukončit a restartovat proces
zapnuto(‘chyba’)
Poslechněte si všechny on('error') události, které jsou vysílány většinou základních objektů Node.js a zejména http . Cokoli, co zdědí nebo vytvoří instanci Express.js, LoopBack, Sails, Hapi atd., bude emitovat error , protože tyto rámce rozšiřují http .
js
server.on('error', function (err) {
console.error(err)
console.error(err)
process.exit(1)
})
uncaughtException
Vždy poslouchejte uncaughtException na process objekt! uncaughtException je velmi hrubý mechanismus pro zpracování výjimek. Neošetřená výjimka znamená, že vaše aplikace – a tím i samotný Node.js – je v nedefinovaném stavu. Slepé pokračování znamená, že se může stát cokoli.
process.on('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
})
nebo
process.addListener('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
Doména
Doména nemá nic společného s webovými doménami, které vidíte v prohlížeči. domain je základní modul Node.js pro zpracování asynchronních chyb uložením kontextu, ve kterém je implementován asynchronní kód. Základní použití domain je vytvořit jeho instanci a vložit svůj havarovaný kód do run() zpětné volání:
var domain = require('domain').create()
domain.on('error', function(error){
console.log(error)
})
domain.run(function(){
throw new Error('Failed!')
})
domain je ve verzi 4.0 mírně zastaralá, což znamená, že hlavní tým Node s největší pravděpodobností oddělí domain z platformy, ale v jádru zatím neexistují žádné alternativy. Také proto, že domain má silnou podporu a použití, bude žít jako samostatný modul npm, takže můžete snadno přepnout z jádra na modul npm, což znamená domain je tady, aby zůstal.
Udělejme chybu asynchronní pomocí stejného setTimeout() :
// domain-async.js:
var d = require('domain').create()
d.on('error', function(e) {
console.log('Custom Error: ' + e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, Math.round(Math.random()*100))
});
Kód se nezhroutí! Zobrazí se nám pěkná chybová zpráva „Vlastní chyba“ z domény error obslužný program události, nikoli vaše typické trasování zásobníku uzlů.
Doplňky C++
Důvodem, proč se Node stal oblíbeným u hardwaru, IoT a robotiky, je jeho schopnost hrát si pěkně s nízkoúrovňovým kódem C/C++. Jak tedy napíšeme vazbu C/C++ pro váš IoT, hardware, dron, chytrá zařízení atd.?
To je poslední hlavní rys této eseje. Většina začátečníků Node si ani nemyslí, že můžete psát své vlastní doplňky C++! Ve skutečnosti je to tak snadné, že to teď uděláme úplně od začátku.
Nejprve vytvořte hello.cc soubor, který má na začátku nějaké standardní importy. Poté definujeme metodu, která vrací řetězec a exportuje tuto metodu.
#include <node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::HandleScope;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); // String
}
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method); // Exporting
}
NODE_MODULE(addon, init)
}
I když nejste odborníkem na C, je snadné zjistit, co se zde děje, protože syntaxe není JavaScriptu tak cizí. Řetězec je capital one :
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one"));`
A exportovaný název je hello :
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method);
}
Jednou hello.cc je připraven, musíme udělat ještě pár věcí. Jedním z nich je vytvoření binding.gyp který má název souboru zdrojového kódu a název doplňku:
{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}
Uložte binding.gyp ve stejné složce jako hello.cc a nainstalujte node-gyp :
$ npm install -g node-gyp
Jakmile získáte node-gyp , spusťte tyto konfigurační a stavební příkazy ve stejné složce, ve které máte hello.cc a binding.gyp :
$ node-gyp configure
$ node-gyp build
Příkazy vytvoří build složku. Zkontrolujte zkompilovaný .node soubory v build/Release/ .
Nakonec napište skript Create Node.js hello.js a zahrňte svůj doplněk C++:
var addon = require('./build/Release/addon')
console.log(addon.hello()) // 'capital one'
Chcete-li spustit skript a zobrazit náš řetězec capital one , jednoduše použijte:
$ node hello.js
Na https://github.com/nodejs/node-addon-examples jsou další příklady doplňků C++.
Shrnutí
Kód pro hraní je na GitHubu. Pokud se vám tento příspěvek líbil, zanechte komentář níže. Pokud vás zajímají vzory Node.js, jako je pozorovatel, zpětné volání a konvence uzlů, podívejte se na můj esej Vzory uzlů:Od zpětných volání k pozorovateli.
Vím, že to bylo dlouhé čtení, takže tady je 30sekundové shrnutí:
- Smyčka událostí:Mechanismus za neblokujícím I/O uzlu
- Globální a procesní:Globální objekty a systémové informace
- Emitenty událostí:Vzor pozorovatele Node.js
- Streamy:Vzor velkého objemu dat
- Vyrovnávací paměti:Binární datový typ
- Shluky:Vertikální škálování
- Doména:Asynchronní zpracování chyb
- C++ Addons:Nízkoúrovňové doplňky
Většina Node je JavaScript s výjimkou některých základních funkcí, které se většinou zabývají systémovým přístupem, globálními aspekty, externími procesy a nízkoúrovňovým kódem. Pokud těmto konceptům rozumíte (neváhejte si tento článek uložit a přečíst si ho ještě několikrát), budete na rychlé a krátké cestě ke zvládnutí Node.js.